结构MySQL存储实现树形结构算法(mysql存储树形)
MySQL存储实现树形结构算法
树形结构算法是一种常见的算法,可以有效地组织和管理数据。它的结构极其灵活,可以表示复杂的逻辑关系,这使得它特别适合用于存储数据集。尽管树形结构在功能上十分强大,但它所需的空间也很高。本文介绍的就是如何使用MySQL来存储树形结构的算法,从而节省空间,最大限度地发挥树形结构的优势。
我们可以使用以下几种方法来实现树形结构算法:1.深度优先算法;2. 广度优先算法;3. 树表表示法;4. 嵌套集表示法。
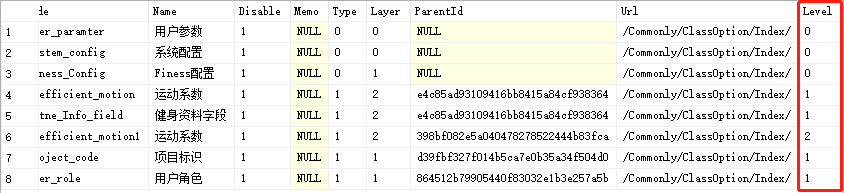
在用MySQL实现树形结构时,最常用的是树表表示法(Tree Table Representation)。使用树表表示法,我们只需要一张表,它有j个字段:结点ID、父ID、结点级别、(可选)是否叶子结点、(可选)子结点个数等。另外,为了快速查询、插入和删除,应该创建一个唯一索引(unique index),以结点ID为关键字。以下代码演示了如何创建唯一索引:
CREATE TABLE Tree (id int NOT NULL, parent_id int, level int, is_leaf boolean DEFAULT FALSE, no_children int DEFAULT 0,
UNIQUE INDEX id_index (ID ASC));
接下来,我们可以在MySQL中插入和更新结点,用来表示树的不同层次的结构:
INSERT INTO Tree (id, parent_id, level) VALUES
(1, 0, 0),
(2, 1, 1),
(3, 2, 2);
当我们确定需要处理的数据结构时,可以在MySQL中使用深度优先算法和广度优先算法来实现树的不同遍历策略,比如前序遍历,中序遍历,后序遍历等。以下代码演示了如何使用MySQL深度优先算法(DFS)实现树的前序遍历:
DELIMITER $$
DROP PROCEDURE IF EXISTS `DFS_Tree_Visit`$$
CREATE PROCEDURE `DFS_Tree_Visit` (IN id int)
BEGIN
— Visit the node
SELECT * FROM Tree WHERE id=id;
— Visit the left subtree
DECLARE pid int;
SELECT parent_id INTO pid FROM Tree WHERE id=id;
IF pid != 0 THEN
CALL DFS_Tree_Visit(pid);
END IF;
— Visit the right subtree
DECLARE next_id int;
SELECT min(id) INTO next_id FROM Tree WHERE id>id;
IF next_id != 0 THEN
CALL DFS_Tree_Visit(next_id);
END IF;
END$$
DELIMITER ;
最后,考虑到MySQL的性能,我们可以根据数据库实际情况,对相关的索引和查询语句进行再优化,以提高查询的性能。
总的来说,MySQL的灵活的数据结构和多种存储算法,使得存储树形结构的任务变得简单快捷。不仅可以极大地节约空间,而且在有需要的时候可以使用这些算法来快速查询,更新和删除数据,有效地应用树形结构的优势。