
Mysql原理 InnoDB聚簇索引二级索引联合索引特点
一、聚簇索引
其实之前内容中介绍的 B+ 树就是聚簇索引。
这种索引不需要我们显示地使用 INDEX 语句去创建,InnoDB 引擎会自动创建。另外,在 InnoDB 引擎中,聚簇索引就是数据的存储方式。
它有 2 个特点:
特点 1
使用记录主键值的大小进行记录和页的排序。
其中又包含了下面 3 个点:
- 页(包括叶节点和内节点)内的记录按照主键的大小顺序排成一个单向链表。页内记录划分为若干组,每个组中主键值最大的记录在页内的偏移量被当做槽依次存放在页目录中。我们可以通过二分法快速定位主键值等于某个值的记录。
- 各存放用户记录的页也是根据页中用户记录的主键大小顺序排成一个双向链表。
- 各存放目录项记录的页分为不同层级。在同一层级中的页,也是根据页中目录项记录的主键大小顺序排成一个双向链表。
特点 2
B+树的叶子节点存储的是完整的用户记录。
这里完整的用户记录就是指,这个记录中存储了所有的列的值(包括隐藏列)。
二、二级索引
聚簇索引只能在我们搜索主键值时才能发挥作用,因为 B+ 树中的数据都是按照主键进行排序。
如果现在我用“别的列”作为搜索条件,怎么办?
答案:再建一个 B+ 树,用这个“别的列”(非主键列)的值大小作为排序规则。
比如之前的内容都是以 c1 列为主键,现在用 c2 列再来创建一个 B+ 树:
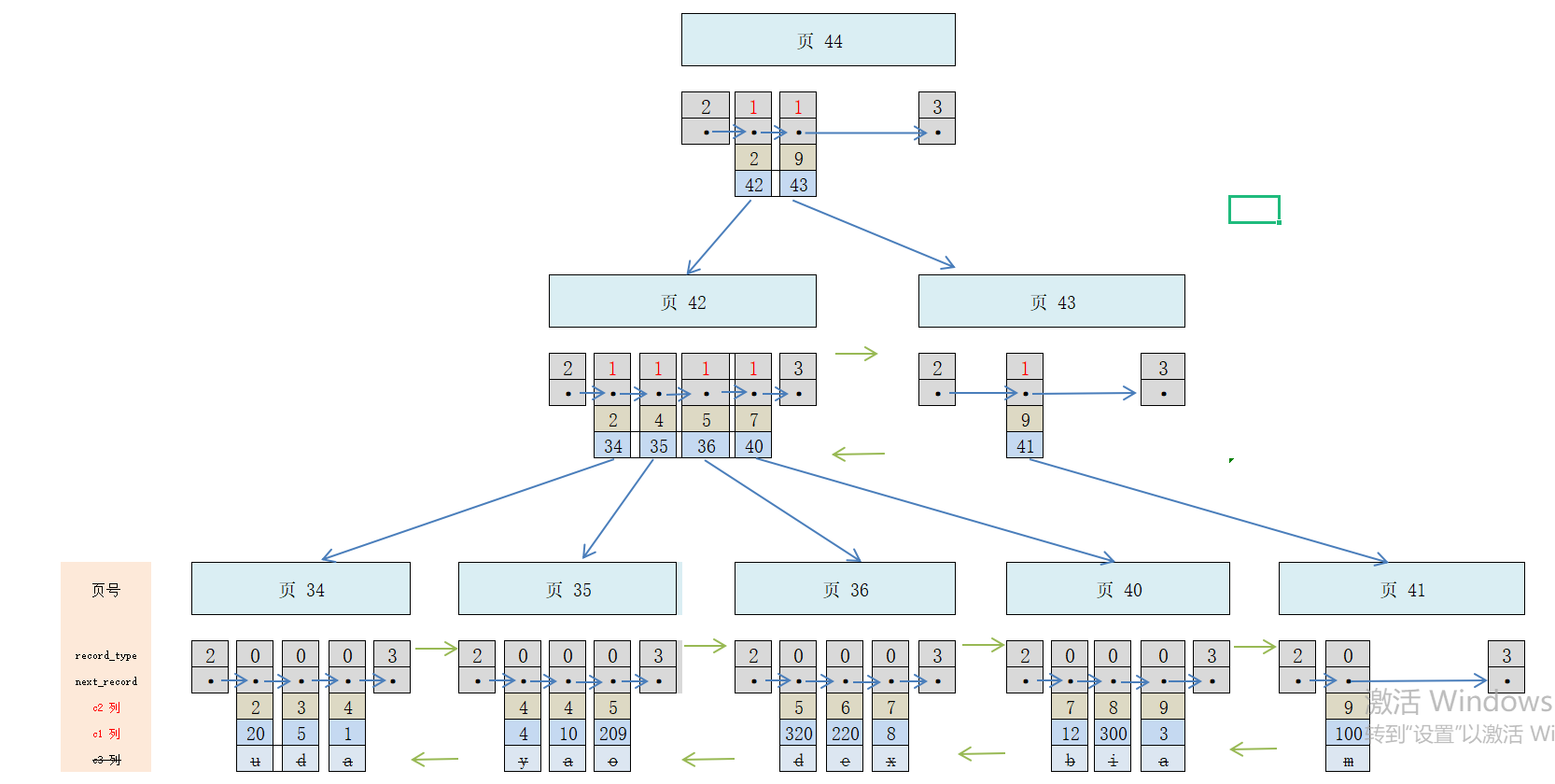
看起来跟之前的聚簇索引没啥区别啊?实际上还是存在不同的:
- 使用记录 c2 列的大小进行记录和页的排序。细分的 3 点与上面聚簇索引介绍的一样,只不过上面是主键,这里是用的 c2 列(非主键)。
- B+ 树的叶子节点存储的不是完整的用户记录,只有c2 列 + 主键这2个列的值。
- 目录项记录中不再是主键 + 页号,变成了c2 列 + 页号。
另外需要注意的是,因为 c2 列不是主键,所以没有唯一性约束,可能存在多条满足搜索条件的数据。
现在根据条件 c2 = 4 来查找数据记录,过程如下:
确定第一条符合 c2 = 4 的目录项所在页,也就是页 42。
到页 42 中,进一步确定第一条符合条件的记录所在的用户记录页。因为 2 < 4 <= 4,所以可能存在 页 34 或 35 中。
先到页 34 中定位第一条满足 c2 = 4 的用户记录,如果有就不需要再到页 35 中继续定位了。
在页 34 中定位到第一条记录。因为这条用户记录不完整,所以拿到这条记录的主键,再到聚簇索引中找到完整的用户记录。
上面最后一步,通过携带主键信息到聚簇索引中重新定位完整的用户记录的过程也叫回表。
回表后,再回到这颗新的 B+ 树,找到刚才那个第一个符合条件的记录,并沿着记录的单向链表向后继续搜索其他也满足 c2 = 4 的记录,每找到一条就继续回表操作,重复这个过程。
这种以非主键列的大小为排序规则而建立 B+ 树需要执行回表操作才可以定位到完整的用户记录,这种 B+树就称为二级索引或者辅助索引。
为什么要回表?直接把完整用户记录都放叶子节点不就可以了?
没错,思路没问题。但是这样操作就相当于每建立一颗 B+ 树都把所有的用户记录复制一遍,太浪费存储空间。
三、联合索引
我们可以同时为多个列建立索引,比如 c2 列和 c3 列,以这 2 个列的大小为排序规则建立的 B+ 树索引就称为联合索引,也称为符合索引或多列索引。
这里的按照 c2 和 c3 列大小进行排序,需要注意两点:
- 先把各个记录和页按照 c2 列进行排序。
- 在记录的 c2 列都相同的情况下,再采用 c3 列进行排序。
现在,给c2 和 c3 建立联合索引,如图所示:
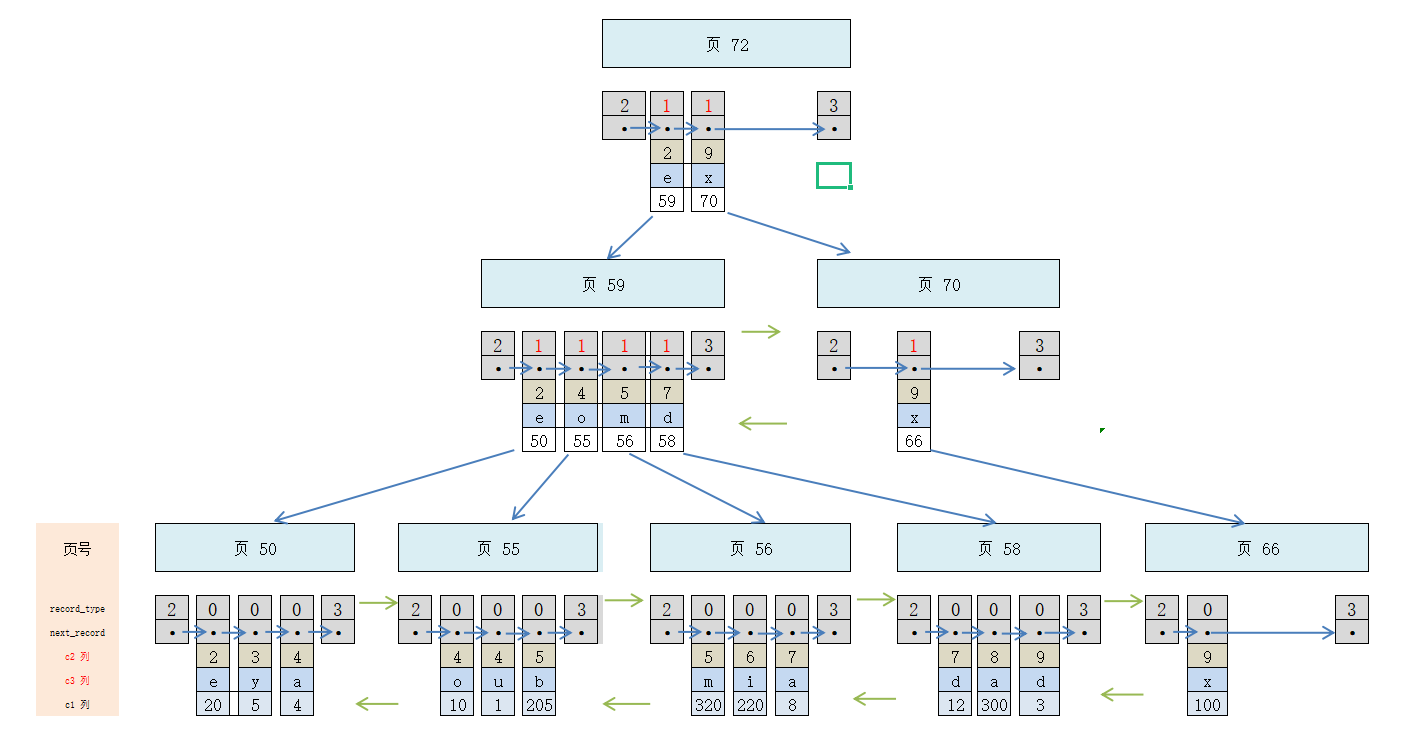
需要注意的是:
- 每条目录项记录都是由 c2、c3、页号这 3 部分组成。各记录先按照 c2 列的值进行排序,如果记录的 c2 列相同,则按照 c3 列进行排序。
- B+ 树叶子节点的用户记录由 c2、c3、和 主键c1 列组成。
本质上,联合索引也是一个二级索引,只不过它的索引列包括 c2、c3 这2个列。
本文参考书籍:《mysql是怎样运行的》
一、聚簇索引
其实之前内容中介绍的 B+ 树就是聚簇索引。
这种索引不需要我们显示地使用 INDEX 语句去创建,InnoDB 引擎会自动创建。另外,在 InnoDB 引擎中,聚簇索引就是数据的存储方式。
它有 2 个特点:
特点 1
使用记录主键值的大小进行记录和页的排序。
其中又包含了下面 3 个点:
- 页(包括叶节点和内节点)内的记录按照主键的大小顺序排成一个单向链表。页内记录划分为若干组,每个组中主键值最大的记录在页内的偏移量被当做槽依次存放在页目录中。我们可以通过二分法快速定位主键值等于某个值的记录。
- 各存放用户记录的页也是根据页中用户记录的主键大小顺序排成一个双向链表。
- 各存放目录项记录的页分为不同层级。在同一层级中的页,也是根据页中目录项记录的主键大小顺序排成一个双向链表。
特点 2
B+树的叶子节点存储的是完整的用户记录。
这里完整的用户记录就是指,这个记录中存储了所有的列的值(包括隐藏列)。
二、二级索引
聚簇索引只能在我们搜索主键值时才能发挥作用,因为 B+ 树中的数据都是按照主键进行排序。
如果现在我用“别的列”作为搜索条件,怎么办?
答案:再建一个 B+ 树,用这个“别的列”(非主键列)的值大小作为排序规则。
比如之前的内容都是以 c1 列为主键,现在用 c2 列再来创建一个 B+ 树:
看起来跟之前的聚簇索引没啥区别啊?实际上还是存在不同的:
- 使用记录 c2 列的大小进行记录和页的排序。细分的 3 点与上面聚簇索引介绍的一样,只不过上面是主键,这里是用的 c2 列(非主键)。
- B+ 树的叶子节点存储的不是完整的用户记录,只有c2 列 + 主键这2个列的值。
- 目录项记录中不再是主键 + 页号,变成了c2 列 + 页号。
另外需要注意的是,因为 c2 列不是主键,所以没有唯一性约束,可能存在多条满足搜索条件的数据。
现在根据条件 c2 = 4 来查找数据记录,过程如下:
确定第一条符合 c2 = 4 的目录项所在页,也就是页 42。
到页 42 中,进一步确定第一条符合条件的记录所在的用户记录页。因为 2 < 4 <= 4,所以可能存在 页 34 或 35 中。
先到页 34 中定位第一条满足 c2 = 4 的用户记录,如果有就不需要再到页 35 中继续定位了。
在页 34 中定位到第一条记录。因为这条用户记录不完整,所以拿到这条记录的主键,再到聚簇索引中找到完整的用户记录。
上面最后一步,通过携带主键信息到聚簇索引中重新定位完整的用户记录的过程也叫回表。
回表后,再回到这颗新的 B+ 树,找到刚才那个第一个符合条件的记录,并沿着记录的单向链表向后继续搜索其他也满足 c2 = 4 的记录,每找到一条就继续回表操作,重复这个过程。
这种以非主键列的大小为排序规则而建立 B+ 树需要执行回表操作才可以定位到完整的用户记录,这种 B+树就称为二级索引或者辅助索引。
为什么要回表?直接把完整用户记录都放叶子节点不就可以了?
没错,思路没问题。但是这样操作就相当于每建立一颗 B+ 树都把所有的用户记录复制一遍,太浪费存储空间。
三、联合索引
我们可以同时为多个列建立索引,比如 c2 列和 c3 列,以这 2 个列的大小为排序规则建立的 B+ 树索引就称为联合索引,也称为符合索引或多列索引。
这里的按照 c2 和 c3 列大小进行排序,需要注意两点:
- 先把各个记录和页按照 c2 列进行排序。
- 在记录的 c2 列都相同的情况下,再采用 c3 列进行排序。
现在,给c2 和 c3 建立联合索引,如图所示:
需要注意的是:
- 每条目录项记录都是由 c2、c3、页号这 3 部分组成。各记录先按照 c2 列的值进行排序,如果记录的 c2 列相同,则按照 c3 列进行排序。
- B+ 树叶子节点的用户记录由 c2、c3、和 主键c1 列组成。
本质上,联合索引也是一个二级索引,只不过它的索引列包括 c2、c3 这2个列。
本文参考书籍:《mysql是怎样运行的》
以上就是Mysql InnoDB聚簇索引二级索引联合索引特点详解的详细内容,更多关于Mysql InnoDB聚簇二级联合索引的资料请关注其它相关文章!
