
如何利用云原生数仓 Databend 构建 MySQL 的归档分析服务
MySQL 归档服务需求分析
MySQL 常用 OLTP 业务环境,一般会使用比较好的硬件资源来提供对外服务。现在 MySQL 数据对外提供的数据动不动好几个 T 也是正常的。在很多业务中,数据有较强的生命周期,在线一段时间后,可能就是失去业务意义,如:
- 某个业务下线
- 业务数据超过服务周期,例如某个业务只需要近 3 个月的数据
- 业务操作的日志类型的数据进行归档
- 分库分表的数据库需要合并到同一个地方,提供统计查询及分析能力
- 定期的备份归档,提供审计工作进行查询使用
这类工作是 DBA 提出归档方案,由开发人员提出对哪些数据可以归档,规范后可以借助于自动化的执行完成。
常见 MySQL 归档处理的方式
现在常见的归档方式一般分成两大类:MySQL & MariaDB,核心工具是:pt-archive 或是解析 binlog 获取归档的数据。
- 首先说第一类使用 MySQL 存储归档
这类方案中,一般是通过购买 PC 机,通常是大容量(50T左右),大内存机型,可以跑实例,来对线上的生产库进行归档。甚至是备份同步。这种场景是最常见的。甚至见到在线下建一个主从,对 PolarDB 进行归档对外提供线下内网查询。
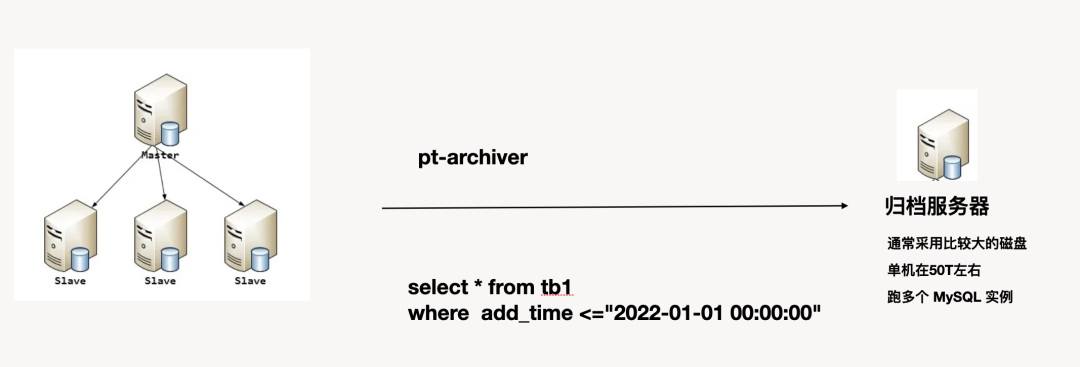
该方式的优点:
- 基于 MySQL 环境,大家都熟悉好管理
- 和线上环境基本能保持同一个版本及高度的兼容
- 归档环境可以使用大容量便宜的磁盘构建
当然这种归档服务也有以下的缺点:
- 这种架构通常为了成本,归档节点通常没开启 Binlog,真正的备份还会放到对象存储中一份,也没有从库,如果发生数据损坏,或是硬盘损坏,数据恢复周期长。
- 计算能力不够,基本没有能力对计算节点扩展,如果需要计算,通常需要把数据抽出来放到大数据环境中计算。
- 这种架构存在大量的 CPU 和 RAM 资源的闲置
- 第二类:使用 MariaDB 归档
MariaDB 推出一个实验特性:S3 engine 该引擎有较高的较压缩能力,基本也保持了 MySQL 的使用习惯。归档流程:先写 InnoDB,然后 alter table tb_name engine=s3;
该方案的优点:
- 基本保持了 MySQL 兼容能力
- 存储上支持 s3 类对象存储
- 支持高压缩存储
该方案的缺点:
- s3 引擎只能读,不能写
- 不支持增加写入,如需改变还需要转成 InnoDB 表
- 每次 InnoDB 到 s3 引擎的转换需要非常长的时间,增加了复杂度
那么现在有没有更完美的方案呢?这里给大家给推荐云原生数仓 Databend
Databend 可以提供的归档方式
Databend 架构及介绍
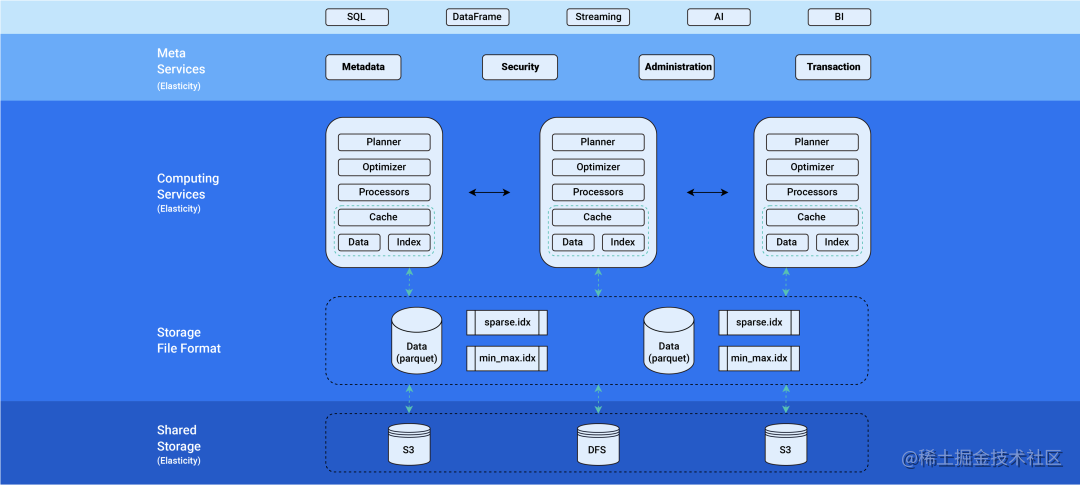
Databend 是一个使用 Rust 研发、开源、完全面向云架构的新式数仓,提供极速的弹性扩展能力,致力于打造按需、按量的 Data Cloud 产品体验。具备以下特点:
- 开源 Cloud Data Warehouse 明星项目
- Vectorized Execution 和 Pull&Push-Based Processor Model
- 真正的存储、计算分离架构,高性能、低成本,按需按量使用
- 完整的数据库支持,兼容 MySQL,Clickhouse 协议,SQL Over HTTP 等
- 完善的事务性,支持 Time Travel,Database Clone,Data Share 等功能
- 支持基于同一份数据的多租户读写、共享操作
Databend 设计上的原则:
1.No Partition
2.No index(Auto Index)
3.Support Transaction
4.Data Time travel/Data Zero copy clone/Data Share
5.Enough Performance/Low Cost
部署方式

支持 MySQL,Clickhouse,SQL Over Http 三种方式的处理。
安装方式参考:https://databend.rs/doc/deploy
安装及使用中如果遇到问题,请添加 Wx: 82565387 获得支持。
数据写入方式
Insert into 写入
支持 jdbc, python, golang 进行 insert 写入,推荐阅读:https://databend.rs/doc/develop
如果要使用 insert 写入,建议使用 Bulk insert 增加批量写入。这个使用上和 MySQL 没有什么区别,所以这里就不过多介绍了。
Streaming load
Streaming load 语法参考:https://databend.rs/doc/load-data/local
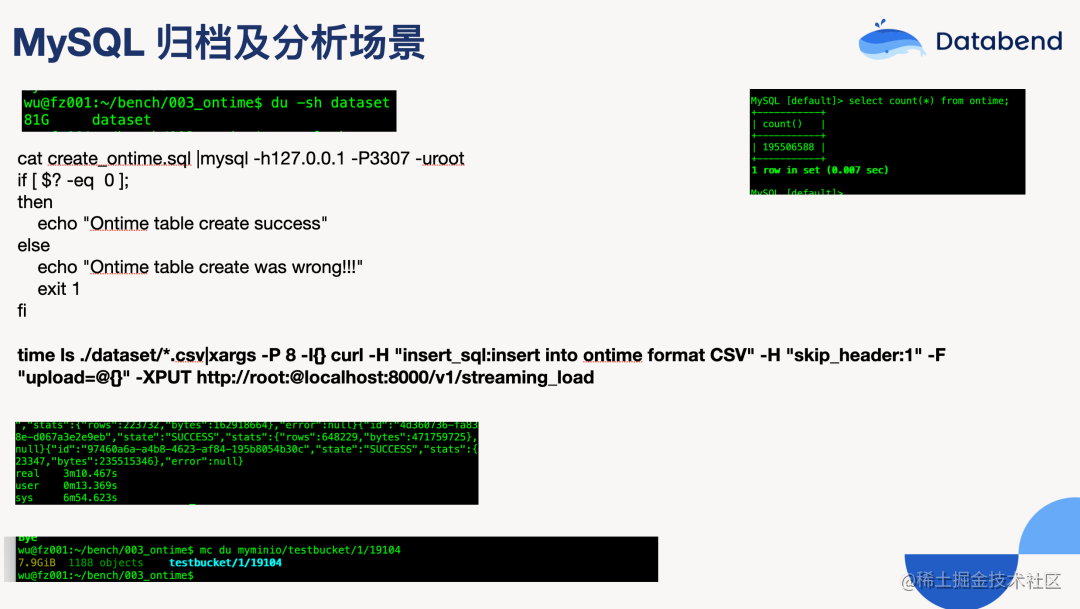
从上面图上可以看到 81 G 的文件,近 2 亿数据导入 Databend 只需要 3 分钟多一点。
另外现在 Databend 也支持直接读取压缩文件。例如:
读取压文件这块只是功能上跑通,但性能上不是最佳的方式,同样的数据使用压缩文件读取,现在大概需要 13 分钟,这个后续应该有不少空间可以提升。
基于 stage 写入
Stage 可以理解 Databend 的一个网盘管理功能。具体语法参考:https://databend.rs/doc/load-data/stage

在以上 PPT 中展示了 stage 的创建,文件上传,文件查看,通过 copy into 的命令可以把 Stage 的文件直接加载到 Databend 的表中。
利用 Databend 归档 MySQL 获得的优势
对于需要考虑 MySQL 归档的场景,建议可以考虑使用 Databend 加对象存储来替代,这样的方式的优点:
- 基于对象存储基本可以实现容量无限
- Databend 数据压缩比较高,正常情下可以做到 10:1, 降低存储空间
- 可以基于 MySQL 协议管理数据,对使用上基本可以做到没有任何变化
- 存算分离架构,对于计算层不足的情况下,可以非常方便的扩容,也无须担心存储的高可用
- 原来 MySQL 生态的工具基本可以重用
Databend 现在对象存储支持:AWS S3, Azure, 阿里云,腾讯云,青云,金山云以及 minio,ceph 等设备。同时 Databend 的计算能力惊力,如果需要分析,可以直接 Databend 直接进行计算。
利用 Databend 可以帮着用更方便的使用好云上的资源,让用户可以获得足够的性能及较低的成本。如果你对该方案有兴趣了解更多,也可以添加 v 信:82565387 进行交流。
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式数仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
- Databend 文档:https://databend.rs/
- Twitter:https://twitter.com/Datafuse_Labs
- Slack:https://datafusecloud.slack.com/
- Wechat:Databend
- GitHub :https://github.com/datafuselabs/databend
