
教你如何优化 MySQL 查询语句的速度,提升性能?
您可以在阿里云上部署快速、安全、可信的 MySQL 数据库实例。阿里巴巴拥有先进的基于云的技术网络,其突破性的性能和灵活的计费,为超过 100 万付费客户实现了云无国界。
阿里云继续为开源社区做出巨大贡献,并为全球开发者赋能。阿里云是享有盛誉的 2018 年 MySQL 企业贡献者奖的获得者,也是 MariaDB 基金会的白金赞助商。
在本指南中,我们将引导您完成在阿里云弹性计算服务 (ECS) 实例上优化 SQL 查询和数据库的步骤。这将保证在您的阿里云实例上运行的应用程序和网站的稳定性、可扩展性、可靠性和速度。
前提条件
- 有效的阿里云账号。如果您还没有,您可以注册阿里云并享受价值 300 美元的免费试用。
- 运行您喜欢的可以支持 MySQL 的操作系统(例如 Ubuntu、Centos、Debian)的服务器。
- MySQL 数据库服务器。
- 能够运行 root 命令的 MySQL 用户。
1. 索引“where”、“order by”和“group by”子句中使用的所有列
除了保证唯一可识别的记录外,索引还允许 MySQL 服务器更快地从数据库中获取结果。在对记录进行排序时,索引也非常有用。
MySQL 索引可能会占用更多空间并降低插入、删除和更新的性能。但是,如果您的表超过 10 行,它们可以大大减少选择查询的执行时间。
始终建议使用“最坏情况”样本数据量测试 MySQL 查询,以便更清楚地了解查询在生产中的行为方式。
考虑这样一种情况,您正在从一个有 500 行但没有索引的数据库中运行以下 SQL 查询:
mysql> select customer_id, customer_name from customers where customer_id='140385';
上述查询将强制 MySQL 服务器进行全表扫描(从开始到结束)以检索我们正在搜索的记录。
幸运的是,MySQL 有一个特殊的“EXPLAIN”语句,您可以将其与 select、delete、insert、replace 和 update 语句一起使用来分析您的查询。
在 SQL 语句之前附加查询后,MySQL 会显示来自优化器的有关预期执行计划的信息。
如果我们使用 explain 语句再次运行上述 SQL,我们将全面了解 MySQL 将如何执行查询:
mysql> explain select customer_id, customer_name from customers where customer_id='140385';
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | customers | NULL | ALL | NULL | NULL | NULL | NULL | 500 | 10.00 | Using where |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
可以看到,优化器显示了非常重要的信息,可以帮助我们微调数据库表。首先,很明显 MySQL 将进行全表扫描,因为键列是 ‘NULL’。其次,MySQL 服务器已经明确表示它将对我们数据库中的 500 行进行全面扫描。
要优化上述查询,我们可以使用以下语法向“customer_id”字段添加索引:
mysql> Create index customer_id ON customers (customer_Id);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
如果我们再运行一次 explain 语句,我们将得到以下结果:
mysql> Explain select customer_id, customer_name from customers where customer_id='140385';
+----+-------------+-----------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | customers | NULL | ref | customer_id | customer_id | 13 | const | 1 | 100.00 | NULL |
+----+-------------+-----------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
从上面的解释输出中,很明显 MySQL 服务器将使用我们的索引 (customer_Id) 来搜索表。您可以清楚地看到要扫描的行数将是 1。虽然我在一个有 500 条记录的表中运行上述查询,但在查询大型数据集(例如有 100 万行的表)时,索引可能非常有用。
- 使用联合子句优化 Like 语句
有时,您可能希望使用比较运算符“或”对特定表中的不同字段或列运行查询。当 where 子句中使用过多的 ‘or’ 关键字时,可能会使 MySQL 优化器错误地选择全表扫描来检索记录。
联合子句可以使查询运行得更快,特别是如果您有一个可以优化查询一侧的索引和一个不同的索引来优化另一侧。
例如,考虑您正在运行以下查询的情况,其中索引了“first_name”和“last_name”:
mysql> select * from students where first_name like 'Ade%' or last_name like 'Ade%' ;
与使用联合运算符合并 2 个利用索引的独立快速查询的结果的以下查询相比,上面的查询运行速度要慢得多
mysql> select from students where first_name like 'Ade%' union all select from students where last_name like 'Ade%' ;
3.避免带有前导通配符的类似表达式
当查询中有前导通配符时,MySQL 无法使用索引。如果我们在学生表上使用上面的示例,这样的搜索将导致 MySQL 执行全表扫描,即使您已经索引了学生表上的“first_name”字段。
mysql> select * from students where first_name like '%Ade' ;
我们可以使用 explain 关键字来证明这一点:
mysql> explain select * from students where first_name like '%Ade' ;
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | students | NULL | ALL | NULL | NULL | NULL | NULL | 500 | 11.11 | Using where |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
正如您在上面看到的,MySQL 将扫描学生表中的所有 500 行,并使查询变得非常缓慢。
- 利用 MySQL 全文搜索
如果您遇到需要使用通配符搜索数据并且不希望数据库性能不佳的情况,则应考虑使用 MySQL 全文搜索 (FTS),因为它比使用通配符的查询快得多。
此外,当您搜索庞大的数据库时,FTS 还可以带来更好的相关结果。
要为学生样本表添加全文搜索索引,我们可以使用以下 MySQL 命令:
mysql>Alter table students ADD FULLTEXT (first_name, last_name);
mysql>Select * from students where match(first_name, last_name) AGAINST ('Ade');
在上面的示例中,我们指定了要与搜索关键字 (‘Ade’) 匹配的列(first_name 和 last_name)。
如果我们向优化器查询上述查询的执行计划,我们将得到以下结果:
mysql> explain Select * from students where match(first_name, last_name) AGAINST ('Ade');
+----+-------------+----------+------------+----------+---------------+------------+---------+-------+------+----------+-------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+----------+---------------+------------+---------+-------+------+----------+-------------------------------+
| 1 | SIMPLE | students | NULL | fulltext | first_name | first_name | 0 | const | 1 | 100.00 | Using where; Ft_hints: sorted |
+----+-------------+----------+------------+----------+---------------+------------+---------+-------+------+----------+-------------------------------+
很明显,即使我们学生的数据库有 500 行,也只会扫描一行,这将加快数据库速度。
5.优化你的数据库模式
即使您优化了 MySQL 查询并且未能提出良好的数据库结构,当您的数据增加时,您的数据库性能仍然会停止。
规范化表
首先,规范化所有数据库表,即使它会涉及一些权衡。例如,如果您要创建两个表来保存客户数据和订单,您应该使用客户 ID 来引用订单表上的客户,而不是在订单表上重复客户的姓名。后者将导致您的数据库膨胀。
下图指的是为性能而设计的数据库架构,没有任何数据冗余。在 MySQL 数据库规范化中,您应该在整个数据库中只表示一次事实。不要在每张表中重复客户名称;而是仅使用 customer_Id 在其他表中进行参考。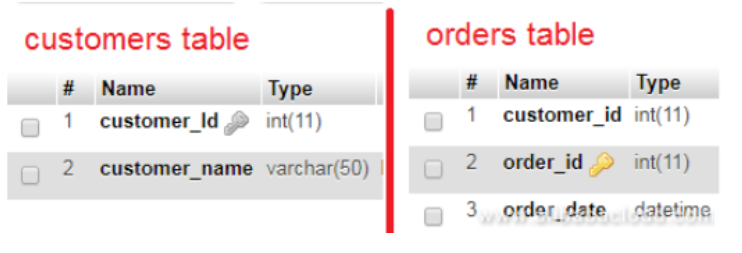
此外,即使它们位于不同的表中,也要始终使用相同的数据类型来存储相似的值,例如,上面的模式使用“INT”数据类型将“customer_id”存储在客户表和订单表中。
使用最佳数据类型
MySQL 支持不同的数据类型,包括 integer、float、double、date、date_time、Varchar 和 text 等。在设计表格时,您应该知道“越短越好”。
例如,如果您正在设计一个包含少于 100 个用户的系统用户表,您应该为“user_id”字段使用“TINYINT”数据类型,因为它将容纳从 -128 到 128 的所有值。
此外,如果字段需要日期值(例如 sales_order_date),则使用 date_time 数据类型将是理想的,因为在使用 SQL 检索记录时,您不必运行复杂的函数将字段转换为日期。
如果您希望所有值都是数字(例如在 student_id 或 payment_id 字段中),请使用整数值。请记住,在计算方面,与 Varchar 等文本数据类型相比,MySQL 使用整数值可以做得更好
避免空值
Null 是列中没有任何值。您应该尽可能避免使用这种值,因为它们会损害您的数据库结果。例如,如果您想获取数据库中所有订单的总和,但特定订单记录的金额为空,则预期结果可能会出现异常,除非您使用 MySQL ‘ifnull’ 语句在记录为空时返回替代值。
在某些情况下,如果记录不必包含该特定列/字段的强制值,您可能需要为该字段定义一个默认值。
避免过多的列
宽表可能开支非常大,并且需要更多的 CPU 时间来处理。如果可能,不要超过一百,除非您的业务逻辑特别要求这样做。
与其创建一个宽表,不如考虑将其拆分为逻辑结构。例如,如果您正在创建一个客户表,但您意识到一个客户可以有多个地址,那么最好创建一个单独的表来保存使用“customer_id”字段引用客户表的客户地址。
优化连接
在连接语句中始终包含更少的表。包含大量连接的设计不良模式的 SQL 语句可能无法正常工作。经验法则是每个查询最多有十几个连接。
- MySQL 查询缓存
如果您的网站或应用程序执行大量选择查询(例如 WordPress),您应该利用 MySQL 查询缓存功能。这将在执行读取操作时提高性能。
该技术通过将选择查询与结果数据集一起缓存来工作。这使得查询运行得更快,因为如果它们被多次执行,它们会从内存中获取。但是,如果您的应用程序频繁更新表,这将使任何缓存的查询和结果集无效。
您可以通过运行以下命令检查您的 MySQL 服务器是否启用了查询缓存:
mysql> show variables like 'have_query_cache';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| have_query_cache | YES |
+------------------+-------+
1 row in <b>set</b> (0.00 sec)
设置 MySQL 服务器查询缓存
您可以通过编辑配置文件(’/etc/mysql/my.cnf’ 或 ‘/etc/mysql/mysql.conf.d/mysqld.cnf’)来设置 MySQL 查询缓存值。这将取决于您的 MySQL 安装。不要设置非常大的查询缓存大小值,因为这会由于缓存开销和锁定而降低 MySQL 服务器的性能。建议使用数十兆字节范围内的值。
要检查当前值,请使用以下命令:
mysql> show variables like 'query_cache_%' ;
+------------------------------+----------+
| Variable_name | Value |
+------------------------------+----------+
| query_cache_limit | 1048576 |
| query_cache_min_res_unit | 4096 |
| query_cache_size | 16777216 |
| query_cache_type | OFF |
| query_cache_wlock_invalidate | OFF |
+------------------------------+----------+
5 rows in <b>set</b> (0.00 sec)
然后调整这些值,在 MySQL 配置文件中包含以下内容:
query_cache_type=1
query_cache_size = 10M
query_cache_limit=256k
您可以根据您的服务器需要调整上述值。
如果默认情况下关闭 MySQL 缓存,指令 ‘query_cache_type=1’ 会打开它。
默认的 ‘query_cache_size’ 是 1MB,就像我们上面所说的,建议使用大约 10 MB 的值。此外,该值必须超过 40 KB,否则 MySQL 服务器将抛出警告“查询缓存无法设置大小”。
默认的“query_cache_limit”也是 1MB。该值控制可以缓存的单个查询结果的数量。
结论
在本指南中,我们向您展示了如何优化托管在阿里云上的 MySQL 服务器以提高速度和性能。
我们相信该指南将使您能够制作更好的查询并拥有结构良好的数据库结构,该结构不仅易于维护,而且可为您的软件应用程序或网站提供更高的稳定性。
