
爬虫技术之分布式爬虫架构的讲解
分布式爬虫架构并不是一开始就出现的。而是一个逐步演化的过程。
最开始入手写爬虫的时候,我们一般在个人计算机上完成爬虫的入门和开发,而在真实的生产环境,就不能用个人计算机来运行爬虫程序了,而是将爬虫程序部署在服务器上。利用服务器不关机的特性,爬虫可以不间断的24小时运行。单机爬虫的结构如下图。
然而,由于爬虫在爬取数据时,爬取频次并不能太快,即使是爬虫在服务器上不间断运行,效率可能也无法满足实际需求。这时候,就需要在多机上部署爬虫程序,用分布式爬虫架构,进行数据爬取。分布式爬虫的架构一般如下所示。
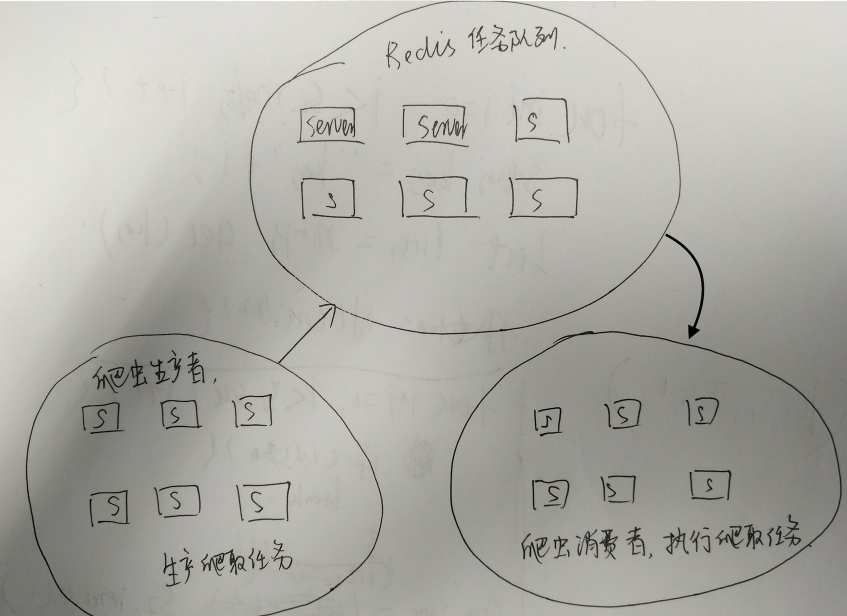
采用分布式爬虫架构后,带来了如下几个好处。
- 1,爬虫效率提高。这一点显而易见,之前是单机运行,现在是多机分布式运行,效率显著提高。
- 2,爬虫可靠性可用性提高。之前部署在一台服务器上,当服务器出现故障或爬虫程序出现故障时,爬虫便不可用了。采用分布式爬虫架构后,爬虫任务生产者,任务队列,爬虫任务消费者都采用分布式架构部署,其中的某些机器出现故障,不影响整体的可用性,系统可靠性大大增强。
总结
本篇文章到此结束,如果您有相关技术方面疑问可以联系我们技术人员远程解决,感谢大家支持本站!
