
浅析redis cluster介绍与gossip协议
一、redis cluster 介绍
- 自动将数据进行分片,每个 master 上放一部分数据
- 提供内置的高可用支持,部分 master 不可用时,还是可以继续工作的
redis cluster架构下的每个redis都要开放两个端口号,比如一个是6379,另一个就是加1w的端口号16379。
- 6379端口号就是redis服务器入口。
- 16379端口号是用来进行节点间通信的,也就是 cluster bus 的东西,cluster bus 的通信,用来进行故障检测、配置更新、故障转移授权。cluster bus 用的是一种叫gossip 协议的二进制协议,用于节点间高效的数据交换,占用更少的网络带宽和处理时间。
二、节点间的内部通信机制
集群元数据的维护有两种方式:集中式、Gossip 协议。
redis cluster 节点间采用 gossip 协议进行通信。
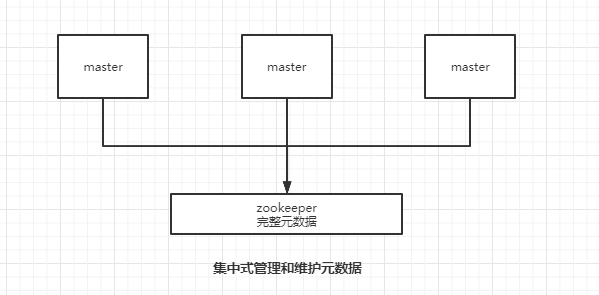
1. 集中式
将集群元数据集中存储在一个节点上。典型代表是大数据领域的 storm。它是分布式的大数据实时计算引擎,是集中式的元数据存储的结构,底层基于 zookeeper对所有元数据进行存储维护。
优点
元数据的读取和更新时效性非常好,元数据的变更都能立即更新到集中式存储节点中,其它节点读取的时候就可以感知到;
缺点
所有的元数据的更新压力全部集中在一个地方,可能会导致元数据的存储有压力。
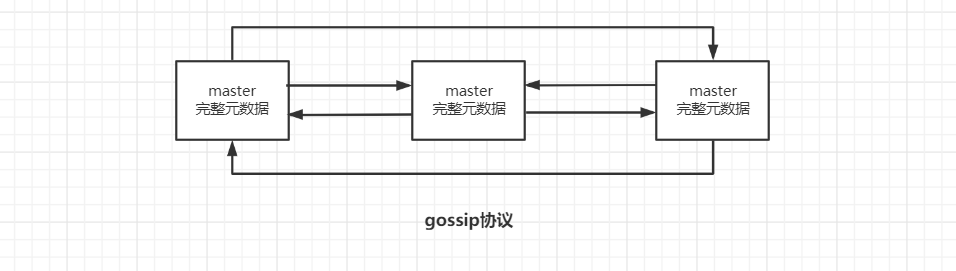
2. gossip 协议
redis 维护集群元数据采用的是gossip 协议,所有节点都持有一份元数据,不同的节点如果出现了元数据的变更,就不断将元数据发送给其它的节点,让其它节点也进行元数据的变更。
优点
元数据的更新比较分散,不是集中在一个地方,降低了压力;
缺点
元数据的更新有延时,可能导致集群中的一些操作会有一些滞后。
三、深入剖析gossip 协议
gossip 协议包含多种消息,包含 ping、pong、meet、fail等等。
meet:某个节点在内部发送了一个gossip meet 消息给新加入的节点,通知那个节点去加入我们的集群。然后新节点就会加入到集群的通信中
redis-trib.rb add-node
- ping:每个节点都会频繁给其它节点发送 ping,其中包含自己的状态还有自己维护的集群元数据,互相通过 ping 交换元数据。
- pong:ping 和 meet消息的返回响应,包含自己的状态和其它信息,也用于信息广播和更新。
- fail:某个节点判断另一个节点 fail 之后,就发送 fail 给其它节点,通知其它节点说这个节点已宕机。
继续深入剖析ping消息
- ping 时要携带一些元数据,如果很频繁,可能会加重网络负担。因此,一般每个节点每秒会执行 10 次 ping,每次会选择 5 个最久没有通信的其它节点。
- 当然如果发现某个节点通信延时达到了 cluster_node_timeout / 2,那么立即发送 ping,避免数据交换延时过长导致信息严重滞后。比如说,两个节点之间都 10 分钟没有交换数据了,那么整个集群处于严重的元数据不一致的情况,就会有问题。所以 cluster_node_timeout 可以调节,如果调得比较大,那么会降低 ping 的频率。
- 每次 ping,会带上自己节点的信息,还有就是带上 1/10 其它节点的信息,发送出去,进行交换。至少包含 3 个其它节点的信息,最多包含 总节点数减 2 个其它节点的信息。
10000 端口:
每个节点都有一个专门用于节点间通信的端口,就是自己提供服务的端口号+10000,比如 6379,那么用于节点间通信的就是16379端口。每个节点每隔一段时间都会往另外几个节点发送 ping 消息,同时其它几个节点接收到 ping 之后返回 pong。
交换的信息:信息包括故障信息,节点的增加和删除,hash slot 信息等等。
总结
到此这篇关于redis cluster介绍与gossip协议的文章就介绍到这了,更多相关redis cluster和gossip协议内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
