
通过实例解析布隆过滤器工作原理及实例
布隆过滤器
布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
布隆过滤器的工作原理
假设一个长度为m的bit类型的数组,即数组中每个位置只占一个bit,每个bit只有两种状态:0,1,所有bit的初始状态都为0。
再假设一共有k个哈希函数,这些函数的输出域大于或者等于m,并且这些哈希函数,彼此之间相互独立,每个哈希函数计算出来的结果是独立的,可能相同也可能不相同,对每一个计算出来的结果都对m取余(%m),然后再将数组下标位置置为1。
我们这里假设m为13,k为3的布隆过滤器,来看看布隆过滤器的工作原理:

当我们要映射一个值到布隆过滤器时,首先计算三个哈希函数的值,然后对13取余,映射到对应位中,图中映射到2,6,10,这样我们就完成了一个值的映射。
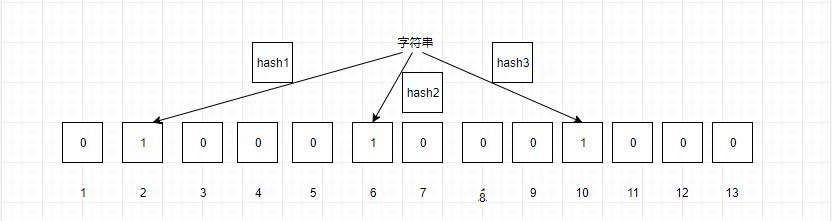
那么怎么判断一个值是否存在,当一个值输入时,通过三个哈希函数,然后取余,我们就可以得到对应的三个位置,我们只需要判断这三个位置是否都为1,如果都为1,则该值存储,反之不存在。
但是有一个特殊情况,前面说了不同的哈希函数可能计算可能相同也可能不相同,而且不同的哈希函数对不同的值计算出来的值可能一样,这就造成一个结果,一个值通过哈希和取余得到的位置,早就被其它值给置1了,当我们存储的值过多,而这个bit数组过小,都会造成这种情况更多的发生,一个值明明不存在,而它的所有位置早就被其它不同值置1,造成了误判,这里就对布隆过滤器提出了一个指标:失误率p。
在同样数据规模下,不同大小的bit数组及不同数量k的哈希函数对误判率的结果:
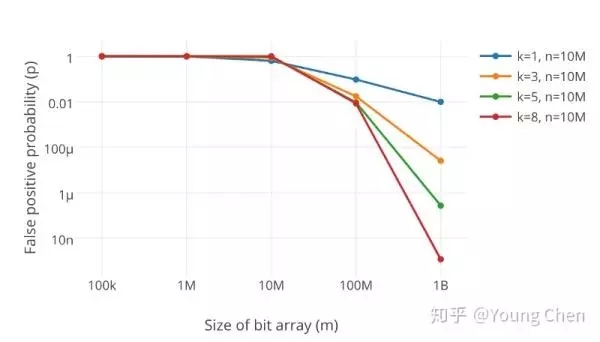
如何选取最合适的m(bit数组的大小)及k(哈希函数的数量),在已知n(需要映射的值得数量)及失误率p的情况下:
m的选取:
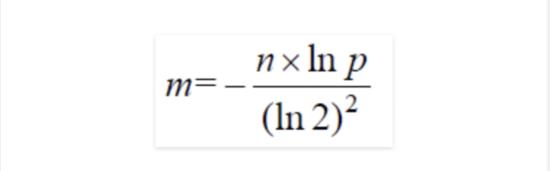
k的选取:

给个例子:假设n=100亿,p=0.01%
通过公式计算出来m=19.19n,向上取整位20n,即2000亿个bit,也就是25gb。
通过公式计算出来k=14。
计算真实失误率:

根据公式计算出来的真实失误率位0.006%。
c语言实现
#include <stdio.h>
#define Size 100
#define BitSIZE Size * 4 * 8
//c语言中一个整型数据类型4个字节
int bit[Size]={0};
int SDBMHash(char *str)
{
unsigned int hash = 0;
while (*str)
{
// equivalent to: hash = 65599*hash + (*str++);
hash = (*str++) + (hash << 6) + (hash << 16) - hash;
}
return (hash & 0x7FFFFFFF);
}
int RSHash(char *str)
{
unsigned int b = 378551;
unsigned int a = 63689;
unsigned int hash = 0;
while (*str)
{
hash = hash * a + (*str++);
a *= b;
}
return (hash & 0x7FFFFFFF);
}
int JSHash(char *str)
{
unsigned int hash = 1315423911;
while (*str)
{
hash ^= ((hash << 5) + (*str++) + (hash >> 2));
}
return (hash & 0x7FFFFFFF);
}
void Insert(int hash){
//int value = hash%BitSIZE; ([0-3200]范围的值)
//int listindex = value / 32; (listindex为数组下标)
//int bitindex = value % 32; (某位)
int value = hash%BitSIZE;
int listindex = value / 32;
int bitindex = value % 32;
int temp = bit[listindex];
bit[listindex] = bit[listindex] & (1 << bitindex);
bit[listindex] = bit[listindex] | temp;
}
int Serach(int hash){
int value = hash%BitSIZE;
int listindex = value / 32;
int bitindex = value % 32;
if (bit[listindex] | (1 << bitindex)){
return 1;
}
return 0;
}
int main () {
char str1[] = "abc123";
//在布隆过滤器中插入某值
Insert(SDBMHash(str1));
Insert(RSHash(str1));
Insert(JSHash(str1));
//在布隆过滤器中判断某值是否存在
int i = 0;
i = i+Serach(SDBMHash(str1));
i = i+Serach(RSHash(str1));
i = i+Serach(JSHash(str1));
if(i == 3){
printf("字符串:%s存在\n",str1);
}
return 0;
}
本篇文章到此结束,如果您有相关技术方面疑问可以联系我们技术人员远程解决,感谢大家支持本站!
