
Redis底层数据结构之dict、ziplist、quicklist详解
此前我们学习了常见的Reids数据类型,这些数据类型都需要底层的数据结构的支持,现在我们来看看Redis常见的底层数据结构:dict、ziplist、quicklist。
1 Redis dict
dict就是“字典”的意思,它是Redis中的一种使用的非常多的底层的数据结构,除了hash会使用字段之外,整个 Redis 数据库的所有 key 和 value 也组成了一个全局字典dict,还有带过期时间的 key 也是一个字典expires(存储在 RedisDb 数据结构中)。
Redis 中的字典相当于 JDK1.7中的 HashMap,内部实现也差不多类似,都是通过 “数组 + 链表” 的链地址法来解决部分哈希冲突,同时这样的结构也吸收了两种不同数据结构的优点。
和JDK1.7中的hashmap不同的是,Reids的字典结构内部包含两个hashtable变量,通常情况下只有一个hashtable有值,另一个为空表,但是在字典扩容缩容时,需要分配新的hashtable,并且使用了一种叫做渐进式搬迁(rehash)的机制来提高dict的缩放效率,这时候两个hashtable分别存储旧的和新的 hashtable,待搬迁结束后,旧的将被删除,新的 hashtable 取而代之。
1.1 扩缩容的条件
正常情况下,当 hash 表中元素的个数等于数组的长度时,就会开始扩容,扩容的新数组是原数组大小的2倍。不过如果 Redis 正在做 BGSAVE或者BGREWRITEAOF(持久化),为了减少内存占用,Redis 尽量不去扩容,但是如果 hash 表非常满了,达到了数组长度的 5 倍了,这个时候就会强制扩容。
当 hash 表因为元素逐渐被删除变得越来越稀疏时,Redis 会对 hash 表进行缩容来减少hash表的第一维数组空间占用。所用的条件是:元素个数低于数组长度的10%,缩容不会考虑 Redis 是否在做 bgsave。
1.2 渐进式rehash操作
在扩容和收缩的时候,如果哈希字典中有很多元素,一次性将这些键从ht0(正在使用的hashtable)全部rehash到ht1(另一个空的hashtable)的话,由于Redis是单线程模型,那么可能会导致服务器在一段时间内停止服务。所以,采用渐进式rehash的方式,数据的迁移并不是一步完成的,因此dict内部还有一个rehashidx属性用来控制rehash,默认置为-1。
- 为ht[1]分配空间,让字典同时持有ht[0]和ht[1]两个哈希表。
- 将rehashindex的值设置为0,表示rehash工作正式开始。
- 在rehash期间,每次对字典执行增删改查操作时,程序除了执行指定的操作以外,还会顺带将ht[0]哈希表在rehashindex索引上的所有键值对rehash到ht[1],当一次rehash工作完成以后,rehashindex的值+1。
- 随着字典操作的不断执行,最终会在某一时间段上ht[0]的所有键值对都会被rehash到ht[1],将rehashindex的值设置为-1,表示rehash操作结束。
- 把ht[1]设置为ht[0],并重新在ht[1]上新建一个空表,为下次rehash做准备。
渐进式rehash采用的是一种分而治之的方式,它以bucket(桶)为基本单位进行渐进式的数据迁移,每步完成一个bucket的迁移,直至所有数据迁移完毕。这种方式将rehash的操作分摊在每一个的访问中,避免集中式rehash而带来的庞大计算量。
在渐进式rehash的过程中,如果有删除、修改、查询操作,则会在两个哈希表ht[0]和ht[1]上进行,先操作ht[0],如果没找到,再操作ht[1],则新增的数据则会被保存在ht[1]中,ht[0]中包含的键值对数量会只减不增,并随着 rehash 操作的执行而最终变成空表。
2 Redis ziplist
ziplist又名压缩列表,见其名知其意,这种数据结构就比较节省内存空间,Redis中对于list(3.2版本之前)、hash、zset类型的数据,如果元素较少,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串,那么Redis就会使用压缩列表来存储。
ziplist本身可以有序也可以无序。当作为list(3.2版本之前)和hash的底层实现时,节点之间没有顺序;当作为zset的底层实现时,节点之间会按照score大小顺序排列,元素和score被分别存储为两个节点,元素在前,score在后。
ziplist的节省空间是相较于数组而言的,ziplist和数组一样同样采用一整块连续的空间来存储数据,数组在实际存储时,每一个元素所占的实际大小是一样的,并且是以最大的元素的大小为准,这样就能进行快速的根据索引访问,而ziplist则允许每一个entry节点(对于数组中的元素)所占的实际大小不同,另外,节点之间没有存储前驱和后继的指针,以此节约空间。
ziplist支持正序或者倒序的遍历,往ziplist里插入一个entry 时间复杂度 平均:O(n),最坏:O(n²),从ziplist里删除一个entry 时间复杂度 平均:O(n), 最坏:O(n²)。最坏为O(n²)是因为Redis连锁更新导致的,但这种情况出现的概率不高。
ziplist和数组类似,删除和添加节点都可能涉及到其他节点位置的移动,因此只适用于元素数据量较少,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串的情况。
2.1 ziplist结构
Redis的ziplist采用一系列特殊编码的连续内存块,一个压缩列表出了在头部包含一些整体信息之外,剩下的部分可以包含任意多个节点(entry)。
整体结构如下:
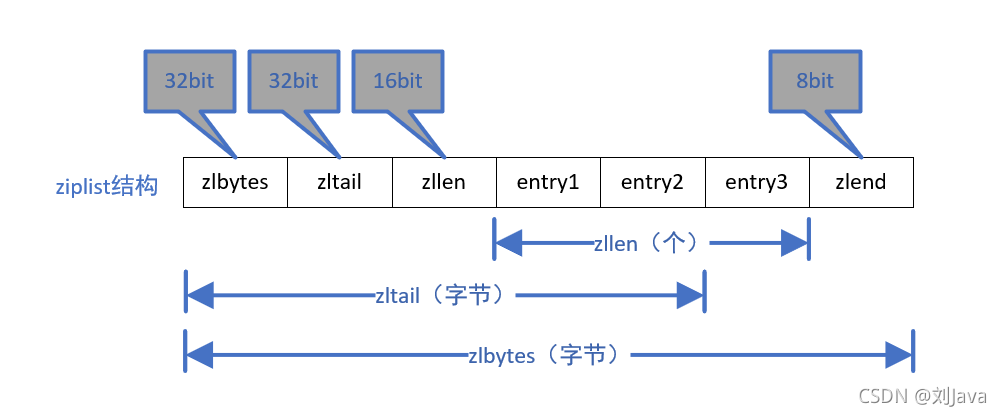
- zlbytes:32位无符号整数,表示ziplist的整体长度(字节)。在对ziplist重新分配内存或者计算zlend的位置时有用。
- zltail:32位无符号整数,最后一个节点距离头部的偏移量,通过该偏移量程序无需遍历整个ziplist即可确定尾节点的地址,在反向遍历ziplist或者pop尾部节点的时候很有用。
- zllen:16位无符号整数,ziplist的节点(entry)个数。当小于值小于65535时,该值时准确的,等于65535(16位的最大值)时,需要遍历整个链表才能得到真实节点数量。
- entry:ziplist中的数据节点,长度不固定,自己的长度保存在每一个entry节点内部。
- zlend:8位无符号整数固定值为0xFF,用于标记ziplist的结尾。
2.2 entry结构
ziplist的entry用于存储正数或者字符串(字节数组),且每个节点的长度都是不一样的,因此节点的长度只能由这个节点自己来保存,Redis的ziplist中,entry由三部分构成:
- previous_entry_length:8bit或者40bit,用于记录上一个节点的长度(字节),为了方便反向遍历ziplist。
- encoding:当前节点数据的编码规则,即data属性的数据类型以及长度。
- content:当前节点的值,可以是数字或字符串(字节数组)。
previous_entry_length用于记录上一个节点的长度(字节),为了方便反向遍历ziplist,其本身的长度可能是8bit或者40bit。
- 如果前一节点的长度小于254字节,那么prevlengh属性的长度为1字节,前一节点的长度就保存在这一个字节里面,这样更加节约内存。
- 如果前一节点的长度大于等于254字节,那么prevlengh属性的总长度为5字节,第一字节被固定设置为0xFE(十进制值254),而之后的四个字节则用于保存前一节点的长度。
- 第二种情况下,第一个字节254而不用255(0xFF)是因为255是zlend的值,它用于判断ziplist是否到达尾部。
content表示当前节点的值,可以是数字或字符串(字节数组),encoding 表示当前节点数据的编码规则,即data属性的数据类型以及长度,其中encoding其中高2位用来区分整数节点和字符串节点(高2位为11时是整数节点),根据值的类型不同,一共有九种编码类型。
字节数组的encoding类型3种,encoding有8位、16位、40位三种长度,context的长度也是变化的:
| encoding长度 | encoding格式 | content格式 |
|---|---|---|
| 8bit | 高两位固定00,后6位表示字节数组的长度 | 长度小于等于63(2^6-1)字节的字节数组 |
| 16bit | 高两位固定01,后14位表示字节数组的长度。 | 长度小于等于16383(2^14-1)字节的字节数组 |
| 40bit | 高两位固定10,后38位表示字节数组的长度。 | 长度小于等于4294967295(2^32-1)字节的字节数组 |
整数值的encoding类型6种,固定长度8位,高两位固定11,表示整数,因此需要后两位来表示不同的整数类型。整数类型的content的长度虽然也是可变的,但固定范围内的整数长度一样,也就是说content长度只有固定的几种。
| encoding长度 | encoding格式 | content格式 |
| 1bit | 1111x,后四位用来表示content。 | 4bit长的无符号整数,即介于0至12之间,没有content字段,在encoding中存储。 |
| 11111110 | 8bit,有符号整数。 | |
| 11000000 | 16bit,有符号整数。 | |
| 11110000 | 24bit,有符号整数。 | |
| 11010000 | 32bit,有符号整数。 | |
| 11100000 | 64bit,有符号整数。 |
3 Redis quicklist
Redis 的list在3.2版本之前在元素较少时实际上是采用ziplist结构,当链表entry数据超过512、或单个value 长度超过64,底层就会转化成linkedlist编码,而Redis3.2及其之后则采用quicklist结构代替ziplist和linkedlist。
ziplist存储在一段连续的内存上,所以存储和查找效率很高,顺序IO访问。但是,它不利于修改操作,插入和删除操作需要频繁的申请和释放内存。特别是当ziplist长度很长的时候,一次realloc可能会导致大批量的数据拷贝,适用于存储整数和短字符串。
双向链表linkedlist便于在表的两端进行push和pop操作,在插入节点上复杂度很低,但是它的内存开销比较大。首先,它在每个节点上除了要保存数据之外,还要额外保存两个prev 和 next指针(64 位操作系统占用 8 个字节);其次,双向链表的各个节点是单独的内存块,地址不连续,随机IO访问,节点多了容易产生内存碎片,影响内存管理效率。
quickList将 linkedList 按段切分,每一段使用 zipList 来紧凑存储,多个 zipList 之间使用双向指针串接起来。
首先quickList就是一个标准的双向链表的配置,有head 和tail节点,每个节点是一个quicklistNode节点,包含prev和next指针,内部还包含一个ziplist,使用ziplist来保存数据,而ziplist实际上含有多个entry节点,保存着数据。相当与一个quicklistNode节点保存的是一片数据,而不再是一个数据。
quickList将二者的优点结合起来,在宏观上是一个双向链表结构,插入、删除quicklistNode节点的成本很低,不需要移动其他节点的位置,而在微观上,每一个quicklistNode节点又是一个个的ziplist,内部包含多个数据,ziplist内存连续,减少了内存碎片,同时由于每一个ziplist不是很大(大小可以配置),因此插入和删除操作不会进行大量的数据移动。
相关文章:
https://redis.io/topics/data-types
https://redis.io/topics/data-types-intro
到此这篇关于Redis的底层数据结构之dict、ziplist、quicklist详解的文章就介绍到这了,更多相关Redis底层数据结构内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
