
Redis高效率原因及数据结构分析
1、什么是redis?它主要用来干什么的?
Redis,英文全称是Remote Dictionary Server(远程字典服务),是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
与MySQL数据库不同的是,Redis的数据是存在内存中的。它的读写速度非常快,每秒可以处理超过10万次读写操作。因此redis被广泛应用于缓存,另外,Redis也经常用来做分布式锁。除此之外,Redis支持事务、持久化、LUA 脚本、LRU 驱动事件、多种集群方案。
知道redis是什么后,接下来我们来说一说redis为什么这么快。
2、redis为什么这么快?

我们来一个一个说明!
基于内存存储实现
计算机专业的同学我们都知道内存读写是要比磁盘快很多的,Redis是基于内存实现的数据库,相对于数据存在磁盘的mysql等数据库,省去了磁盘I/O的消耗。
高效的数据结构
我们都知道,mysql索引为了提高效率,选择了B+树的数据结构,对于一个应用场景来说合理的数据结构可以让你的应用或者程序更快。我们来看看Redis的数据结构–内部编码图:
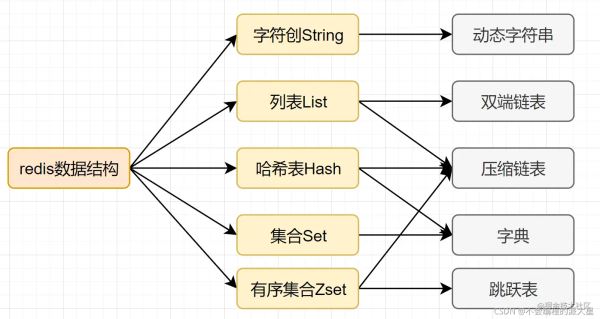
String : 动态字符串SDS
List: 双端链表LinkedList+压缩链表ziplist
Hash: 压缩链表ziplist+字典哈希表hashtable
Set: hashtable(+inset)
Zset: 压缩链表ziplist+跳表skiplist
我们来说一说这几种内部编码:
1、SDS简单动态字符串
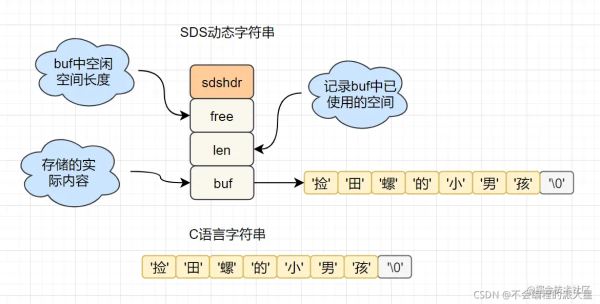
我们来和C语言中的char[ ]对比下
字符串长度处理: Redis获取字符串长度,时间复杂度为O(1),而C语言中,需要从头遍历,复杂度为O(N)。
空间预分配: 字符串修改越频繁的话,内存分配就越频繁,就会很消费性能,而SDS修改和空间扩充,会额外分配未使用的空间,减少性能损耗。
惰性空间释放: SDS缩短时,不是回收多余的内存空间,而是free记录下多余的空间,后续有变更,直接使用free中记录的空间,减少分配。
二进制安全: Redis可以存储一些二进制数据,在C语言中字符串遇到’/0’会结束,而SDS中标志字符串结束的是len属性。
2、字典
Redis 作为 K-V 型内存数据库,所有的键值就是用字典来存储。字典就是哈希表,比如HashMap,通过key就可以直接获取到对应的value。而哈希表的特性,在O(1)时间复杂度就可以获得对应的值。
3、跳表
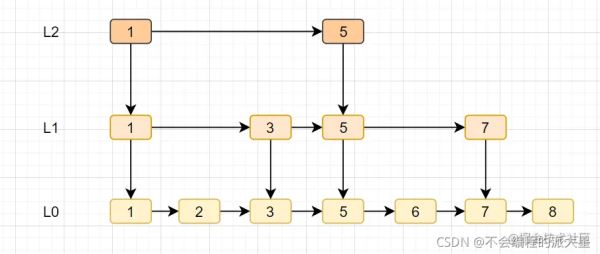
跳表是Redis特有的数据结构,就是在链表的基础上,增加多级索引提升查找效率。
跳表支持平均O(logN),最坏O(N)复杂度的节点查找,还可以通过顺序性操作。
合理的数据编码
Redis 支持多种数据数据类型,每种基本类型,可能对多种数据结构。什么时候,使用什么样数据结构,使用什么样编码,是redis设计者总结优化的结果。
String: 如果存储数字的话,是用int类型的编码;如果存储非数字,小于等于39字节的字符串,是embstr;大于39个字节,则是raw编码。
List: 如果列表的元素个数小于512个,列表每个元素的值都小于64字节(默认),使用ziplist编码,否则使用linkedlist编码
Hash: 哈希类型元素个数小于512个,所有值小于64字节的话,使用ziplist编码,否则使用hashtable编码。
Set: 如果集合中的元素都是整数且元素个数小于512个,使用intset编码,否则使用hashtable编码。
Zset: 当有序集合的元素个数小于128个,每个元素的值小于64字节时,使用ziplist编码,否则使用skiplist(跳跃表)编码。
合理的线程模型
1、I/O多路复用
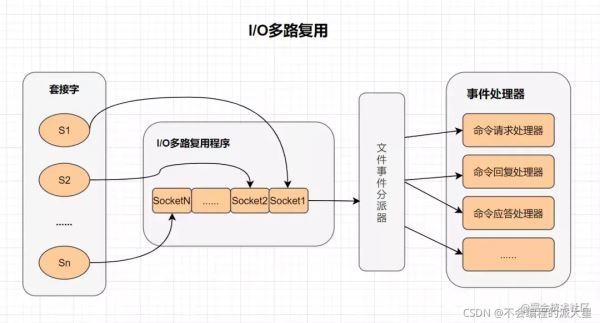
多路I/O复用技术可以让单个线程高效的处理多个连接请求,而Redis使用用epoll作为I/O多路复用技术的实现。并且,Redis自身的事件处理模型将epoll中的连接、读写、关闭都转换为事件,不在网络I/O上浪费过多的时间。
2、什么是I/O多路复用?
I/O : 网络 I/O
多路 : 多个网络连接
复用: 复用同一个线程。
IO多路复用其实就是一种同步IO模型,它实现了一个线程可以监视多个文件句柄;一旦某个文件句柄就绪,就能够通知应用程序进行相应的读写操作;而没有文件句柄就绪时,就会阻塞应用程序,交出cpu。
3、单线程模型
Redis是单线程模型的,而单线程避免了CPU不必要的上下文切换和竞争锁的消耗。也正因为是单线程,如果某个命令执行过长(如hgetall命令),会造成阻塞。Redis是面向快速执行场景的数据库。,所以要慎用如smembers和lrange、hgetall等命令。
Redis 6.0 引入了多线程提速,它的执行命令操作内存的仍然是个单线程。
虚拟内存机制
redis直接自己构建了VM机制,不会像一般的系统会调用系统函数处理,会浪费一定的时间去移动和请求。
Redis的虚拟内存机制是啥呢?
虚拟内存机制就是暂时把不经常访问的数据(冷数据)从内存交换到磁盘中,从而腾出宝贵的内存空间用于其它需要访问的数据(热数据)。通过VM功能可以实现冷热数据分离,使热数据仍在内存中、冷数据保存到磁盘。这样就可以避免因为内存不足而造成访问速度下降的问题。
以上就是Redis高效原因及数据结构分析的详细内容,更多关于Redis的资料请关注其它相关文章!
