
Redis内部数据结构Dict的实现方法
我们平时用Redis的时候,只是了解到了它对外的一些结构,如:string、list、set、hash、zset,但是我们却很少能了解到Redis内部用的存储结构,小编将在这篇文章和大家秀一下Redis中的一个内部结构——dict。
一、dict是什么
不知道大家在用Redis的时候有没有注意到,我们在使用大多数Redis命令的时候,都会让你输入一个key,后面才会让你输入具体的值。
我们本篇文章所述的dict在Redis中最主要的作用就是用于维护Redis数据库中所有Key、value映射的数据结构,也就是我们在输入set、zadd等命令时输入的key与后面值的映射。321,上代码。代码来源(dict.h)。 如下代码所示,dict结构体里面有一个dictht 数组,dictht 里面的dictEntry 就是具体存放key、value映射关系的。
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictht {
dictEntry **table;
unsigned long size; // hashtable 容量
unsigned long sizemask; // size -1
unsigned long used; // hashtable 元素个数 used / size =1
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];// ht[0] , ht[1] =null
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
小贴纸:dictEntry 中用到了union联合体这种结构。也就是多个变量的结构同时使用一块内存区域,区域的取值大小为该结构中长度最大的变量的值。这有利于减少内存碎片,提高内存利用率,在Java中的压缩指针技术就用到了联合体。
二、dict数据结构
1.结构梳理
我们仔细看上面代码中的结构,小编可以直接告诉你,其实它就是一个哈希表结构,在Java中相当于一个HashMap,因为Redis需要保证快速响应,所以选择哈希表作为存储结构是一个不错的决定。我们这里只一起了解结构中存具体数据的部分。
- dictEntry:其实它就是一个链表结构,里面维护了key、value。
- dictht :它维护了一个dictEntry 指针数组。 虽然我们肉眼能看到定义的是指针的指针,dictEntry **table。但其实指针的指针是指向了dictEntry 数组指针的首地址。Redis源码里大多会这么用 table[index]。指针这块有点绕,可以暂时直接认为它就是一个指针数组。
- dict: dict里面维护了一个dictht ht[2] 数组,相当于两个dictht 结构。为什么要存两个dictht 结构呢。因为既然是哈希表那就要涉及到扩容,redis是单线程的,不可能一下子将所有的数据都转移到新的哈希表中,这样可能会造成服务长时间不可用,所以它退而求其次,选择了"渐进式扩容"。
小贴纸:Redis中的渐进式扩容,采用的是在内存中放置两个哈希表结构,无需扩容时,使用的是哈希表0,在扩容期间,将扩容标识设置为true,当有新数据进来的时候,发现正在扩容,就会在将新数据直接放入哈希表1。而表0中的数据会在每次有请求命令并且请求的数据在表0中时,将请求命令涉及到的数据直接挂到表1上。 在扩容期间如果执行查找命令会查找表0+表1的数据。
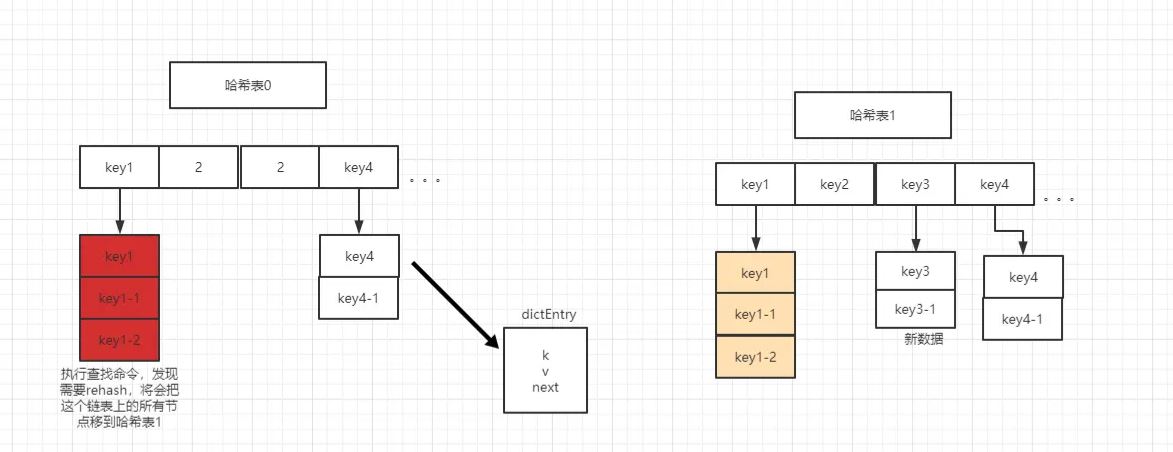
当然,Redis如果一直不执行命令的话。它也会有一个后台定时任务,对字典进行主动搬迁,它不会对未完成的事置之不理
void databaseCron() {
…
if (server.activerehashing) {
for (j = 0; j < dbs_per_call; j++) {
int work_done = incrementallyRehash(rehash_db);
if (work_done) {
/* If the function did some work, stop here, we’ll do
* more at the next cron loop. */
break;
} else {
/* If this db didn’t need rehash, we’ll try the next one. */
rehash_db++;
rehash_db %= server.dbnum;
}
}
}
}
2. 扩容条件
- 当hash表中元素的个数等于数组长度时,就会开始扩容,扩容的新数组是原数组的2倍。
- 当Redis发生其他情况没有在元素个数等于数组长度时扩容,那么Redis会有一个强制扩容的条件,就是元素个数达到数组长度5倍时进行强制扩容。
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* 元素个数大于等于数组长度&&(能扩容(bgsave时尽量不扩容)或元素大于5倍时强制扩容)
* static unsigned int dict_force_resize_ratio = 5;
*/
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
3. 缩容条件
既然有扩容,当前就有缩容,要不占那么大内存不是浪费吗?
- 当元素小于数组长度的10%时进行缩容。
long long size, used;
size = dictSlots(dict);
used = dictSize(dict);
return (size > DICT_HT_INITIAL_SIZE &&
(used*100/size < HASHTABLE_MIN_FILL));
}
dict结构的实现相对来说比较简单,本文就介绍到这。
到此这篇关于Redis内部数据结构Dict的实现方法的文章就介绍到这了,更多相关redis dict数据结构内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
