
Redis实现多级缓存
本文实例为大家分享了Redis实现多级缓存的具体代码,供大家参考,具体内容如下
一、多级缓存
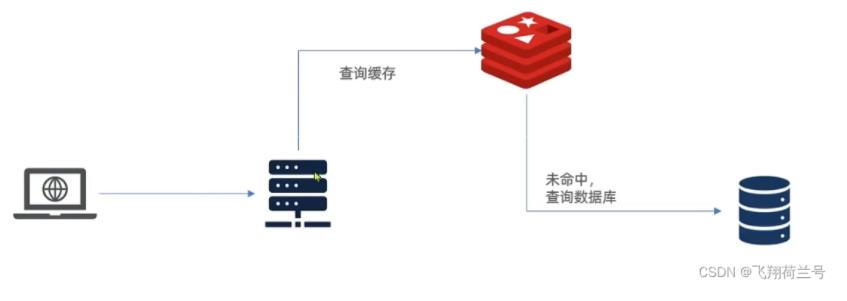
1. 传统缓存方案
请求到达tomcat后,先去redis中获取缓存,不命中则去mysql中获取
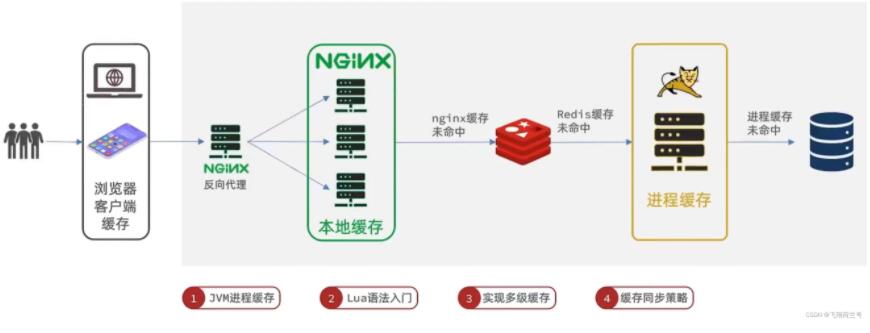
2. 多级缓存方案
- tomcat的请求并发数,是远小于redis的,因此tomcat会成为瓶颈
- 利用请求处理每个环节,分别添加缓存,减轻tomcat压力,提升服务性能
二、JVM本地缓存
缓存是存储在内存中,数据读取速度较快,能大量减少对数据库的访问,减少数据库压力
分布式缓存,如redis
– 优点: 存储容量大,可靠性好,可以在集群中共享
– 缺点: 访问缓存有网络开销
– 场景: 缓存数据量大,可靠性高,需要在集群中共享的数据
进程本地缓存, 如HashMap, GuavaCache
– 优点:读取本地内存,没有网络开销,速度更快
– 缺点:存储容量有限,可靠性低(如重启后丢失),无法在集群中共享
– 场景:性能要求高,缓存数据量少
1. 实用案例
Caffeine是一个基于java8开发的,提供了近乎最佳命中率的高性能的本地缓存库
目前spring内部的缓存用的就是这个
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>3.0.5</version>
</dependency>
import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import java.time.Duration;
public final class CacheUtil {
private static int expireSeconds = 2;
public static Cache<String, String> cacheWithExpireSeconds;
private static int maxPairs = 1;
public static Cache<String, String> cacheWithMaxPairs;
static {
/*过期策略,写完60s后过期*/
cacheWithExpireSeconds = Caffeine.newBuilder()
.expireAfterWrite(Duration.ofSeconds(expireSeconds))
.build();
/*过期策略,达到最大值后删除
* 1. 并不会立即删除,等一会儿才会删除
* 2. 会将之前存储的数据删除掉*/
cacheWithMaxPairs = Caffeine.newBuilder()
.maximumSize(maxPairs)
.build();
}
/*从缓存中获取数据
* 1. 如果缓存中有,则直接从缓存中返回
* 2. 如果缓存中没有,则去数据查询并返回结果*/
public static String getKeyWithExpire(String key) {
return cacheWithExpireSeconds.get(key, value -> {
return getResultFromDB();
});
}
public static String getKeyWithMaxPair(String key) {
return cacheWithMaxPairs.get(key, value -> {
return getResultFromDB();
});
}
private static String getResultFromDB() {
System.out.println(“数据库查询”);
return “db result”;
}
}
import java.util.concurrent.TimeUnit;
public class Test {
@org.junit.Test
public void test01() throws InterruptedException {
CacheUtil.cacheWithExpireSeconds.put(“name”, “erick”);
System.out.println(CacheUtil.getKeyWithExpire(“name”));
TimeUnit.SECONDS.sleep(3);
System.out.println(CacheUtil.getKeyWithExpire(“name”));
}
@org.junit.Test
public void test02() throws InterruptedException {
CacheUtil.cacheWithMaxPairs.put(“name”, “erick”);
CacheUtil.cacheWithMaxPairs.put(“age”, “12”);
System.out.println(CacheUtil.getKeyWithMaxPair(“name”));
System.out.println(CacheUtil.getKeyWithMaxPair(“age”));
TimeUnit.SECONDS.sleep(2);
System.out.println(CacheUtil.getKeyWithMaxPair(“name”)); // 查询不到了
System.out.println(CacheUtil.getKeyWithMaxPair(“age”));
}
}
三、缓存一致性
1. 常见方案
1.1 设置有效期
- 给缓存设置有效期,到期后自动删除。再次查询时可以更新
- 优势:简单,方便
- 缺点:时效性差,缓存过期之前可能不一致
- 场景:更新频率低,时效性要求比较低的业务
1.2 同步双写
- 在修改数据库的同时,直接修改缓存
- 优势:有代码侵入,缓存与数据库强一致性
- 缺点:代码进入,耦合性高
- 场景:对一致性,失效性要求较高的缓存数据
1.3 异步通知
- 修改数据库时发送事件通知,相关服务监听到后修改缓存数据
- 优势:低耦合,可以同时通知多个缓存服务
- 缺点:时效性一把,可能存在缓存不一致问题
- 场景:时效性一般,有多个服务需要同步
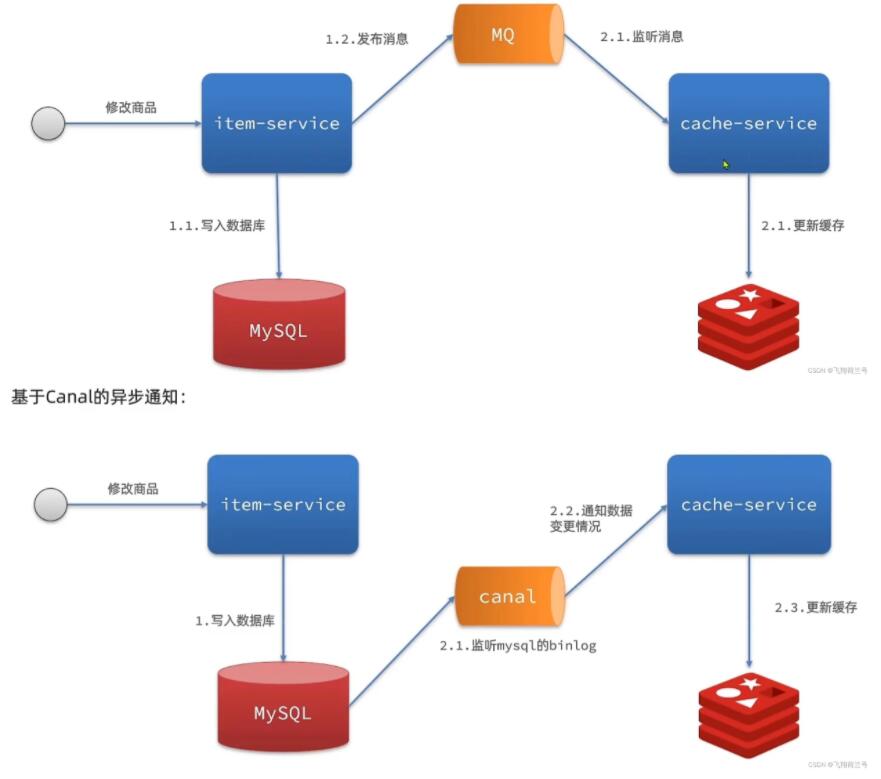
2. 基于Canal的异步通知
- 是阿里旗下的一款开源项目,基于java开发
- 基于数据库增量日志解析,提供增量数据订阅和消费
- 基于mysql的主从备份的思想
2.1 mysql主从复制
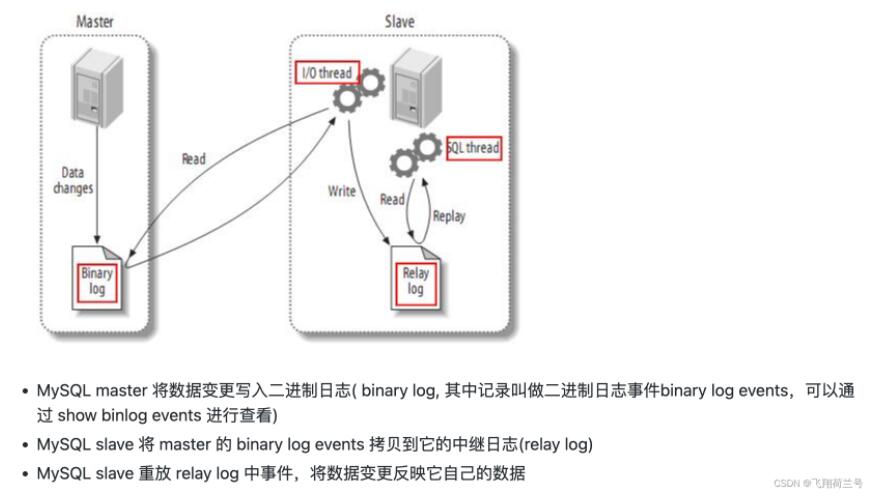
2.2 canal 工作原理
canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
MySQL master 收到 dump 请求, 开始推送 binary log 给 slave (即 canal )
canal 解析 binary log 对象(原始为 byte 流)
本篇文章到此结束,如果您有相关技术方面疑问可以联系我们技术人员远程解决,感谢大家支持本站!
