
修改一行代码提升 Postgres 性能 100 倍
在一个(差)的PostgreSQL 查询中只要一个小小到改动(ANY(ARRAY[…])to ANY(VALUES(…)))就能把查询时间从20s缩减到0.2s。从最简单的学习使用 EXPLAIN ANALYZE开始,到学习使用 Postgres community 大量学习时间的投入将有百倍时间到回报。
使用Postgres监测慢的Postgres查询
在这周早些时候,一个用于我们的图形编辑器上的小表(10GB,1500万行)的主键查询,在我们的一个(多个)数据库上发生来大的查询性能问题。
99.9%到查询都是非常迅速流畅的,但是在一些使用大量的枚举值的地方,这些查询会需要20秒。花费如此多到时间在数据库上,意味着使用者必须在浏览器面前等待图形编辑器的响应。很明显只因为这0.01%就会造成很不好到影响。
查询和查询计划
下面是这个出问题的查询
SELECT c.key,
c.x_key,
c.tags,
x.name
FROM context c
JOIN x
ON c.x_key = x.key
WHERE c.key = ANY (ARRAY[15368196, — 11,000 other keys –)])
AND c.x_key = 1
AND c.tags @> ARRAY[E’blah’];
表X有几千行数据,表C有1500万条数据。两张表的主键值“key”都有适当的索引。这是一个非常简单清晰的主键查询。但有趣的是,当增加主键内容的数量,如在主键有11,000个值的时候,通过在查询语句上加上 EXPLAIN (ANALYZE, BUFFERS)我们得到如下的查询计划。
Nested Loop (cost=6923.33..11770.59 rows=1 width=362) (actual time=17128.188..22109.283 rows=10858 loops=1)
Buffers: shared hit=83494
-> Bitmap Heap Scan on context c (cost=6923.33..11762.31 rows=1 width=329) (actual time=17128.121..22031.783 rows=10858 loops=1)
Recheck Cond: ((tags @> ‘{blah}’::text[]) AND (x_key = 1))
Filter: (key = ANY (‘{15368196,(a lot more keys here)}’::integer[]))
Buffers: shared hit=50919
-> BitmapAnd (cost=6923.33..6923.33 rows=269 width=0) (actual time=132.910..132.910 rows=0 loops=1)
Buffers: shared hit=1342
-> Bitmap Index Scan on context_tags_idx (cost=0.00..1149.61 rows=15891 width=0) (actual time=64.614..64.614 rows=264777 loops=1)
Index Cond: (tags @> ‘{blah}’::text[])
Buffers: shared hit=401
-> Bitmap Index Scan on context_x_id_source_type_id_idx (cost=0.00..5773.47 rows=268667 width=0) (actual time=54.648..54.648 rows=267659 loops=1)
Index Cond: (x_id = 1)
Buffers: shared hit=941
-> Index Scan using x_pkey on x (cost=0.00..8.27 rows=1 width=37) (actual time=0.003..0.004 rows=1 loops=10858)
Index Cond: (x.key = 1)
Buffers: shared hit=32575
Total runtime: 22117.417 ms
在结果的最底部你可以看到,这个查询总共花费22秒。我们可以非常直观的通过下面的CPU使用率图观察到这22秒的花费。大部分的时间花费在 Postgres和 OS 上, 只有很少部分用于I/O .
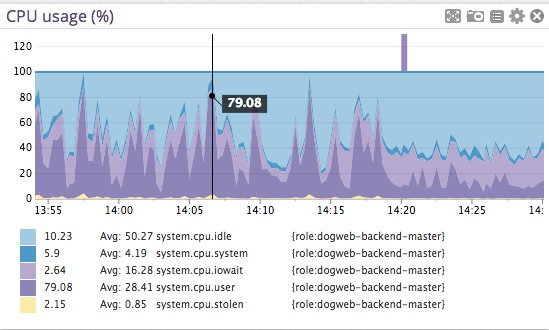
在最低的层面,这些查询看起来就像是这些CPU利用率的峰值。CPU图很少有用,但是在这种条件下它证实了关键的一点:数据库并没有等待磁盘去读取数据。它在做一些排序,哈希以及行比较之类的事情。
第二个有趣的度量,就是距离这些峰值很近的轨迹,它们是由Postgres“取得”的行数(本例中没有返回,就看看再忽略掉吧)。
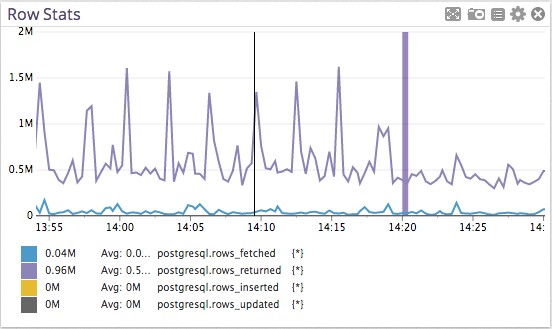
显然有些动作在规则的有条不紊的浏览过许多行:我们的查询。
Postgres 的问题所在:位图扫描
下面是行匹配的查询计划
解决方案
这是我们喜欢开源和喜欢帮助用户的另外一个原因。Tom Lane是开源代码作者中最盛产的程序员之一,他建议我们做如下尝试:
SELECT c.key,
c.x_key,
c.tags,
x.name
FROM context c
JOIN x
ON c.x_key = x.key
WHERE c.key = ANY (VALUES (15368196), — 11,000 other keys –)
AND c.x_key = 1
AND c.tags @> ARRAY[E’blah’];
把ARRAY改成VALUES,你能指出他们的不同点吗?
我们使用ARRAY[…]列举出所有的关键字以用来查询,但是这却欺骗了查询优化器。然而Values(…)却能够让优化器充分使用关键字索引。仅仅是一行代码的改变,并且没有产生任何语义的改变。
下面是新查询语句的写法,差别就在于第三和第十四行。
Buffers: shared hit=44963
Total runtime: 263.639 ms
查询时间从22000ms下降到200ms,仅仅一行代码的改变效率就提高了100倍。
在生产中使用的新查询
即将发布的一段代码:

它使数据库看起来更美观轻松.
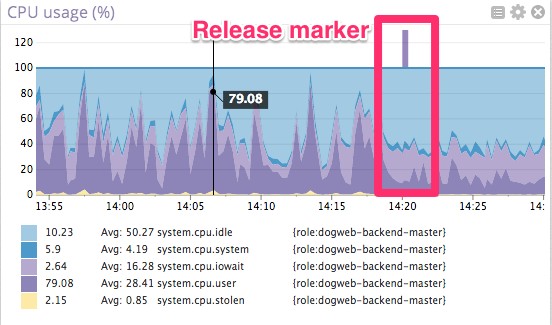
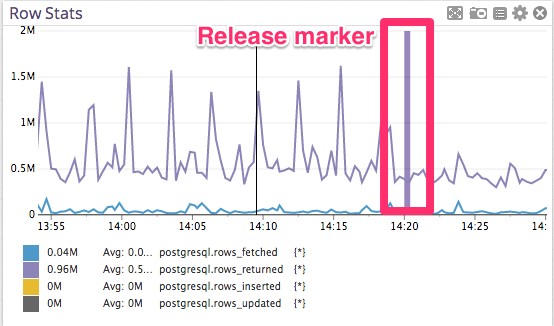
第三方工具
postgres慢查询不存在了。但是有谁乐意被0.1%不幸的少数折磨。要立即验证修改查询的影响,就需要Datadog来帮助我们判断修改是否是正确的。
如果你想要找出对Postgres查询改变的影响,可能需要几分钟来注册一个免费的Datadog账号。
