
redis批量操作pipeline管道操作方法
redis | pipeline(管道)
背景
Redis是一种基于客户端-服务端模型以及请求/响应的TCP服务。这意味着通常情况下一个请求会遵循以下步骤:
- 客户端向服务端发送一个查询请求,并监听 Socket 返回,通常是以阻塞模式,等待服务端响应。
- 服务端处理命令,并将结果返回给客户端。
Redis 客户端与 Redis 服务器之间使用 TCP 协议进行连接,一个客户端可以通过一个 socket 连接发起多个请求命令。每个请求命令发出后 client 通常会阻塞并等待 redis 服务器处理,redis 处理完请求命令后会将结果通过响应报文返回给 client,因此当执行多条命令的时候都需要等待上一条命令执行完毕才能执行。
Redis本身是基于一个Request一个Response方式的同步请求,正常情况下,客户端发送一个命令,等待Redis服务器返回结果,Redis服务器接收到命令,处理后响应结果给客户端。
无论网络延如何延时,数据包总是能从客户端到达服务器,并从服务器返回数据回复客户端。 这个时间被称之为 RTT (Round Trip Time – 往返时间)。
如果同时需要执行大量的命令,那么就要等待上一条命令应答后再执行,这中间不仅仅多了RTT(Round Time Trip),而且还频繁调用系统IO,发送网络请求,同时需要redis调用多次read() 和write()系统方法,系统方法会将数据从用户态转移到内核态,这样就会对进程上下文有比较大的影响了。
什么是流水线(pipeline)
官网:https://redis.io/docs/manual/pipelining/
管道(pipeline)可以一次性发送多条命令并在执行完后一次性将结果返回,pipeline 通过减少客户端与 redis 的通信次数来实现降低往返延时时间,而且 Pipeline 实现的原理是队列,而队列的原理是时先进先出,这样就保证数据的顺序性。
通俗点:pipeline就是把一组命令进行打包,然后一次性通过网络发送到Redis。同时将执行的结果批量的返回回来。
pipeline,将多个命令一次执行,一次发送出去,节省网络时间。 pipeline技术最显著的优势是提高了 redis 服务的性能。
管道技术并不是Redis特有的技术,管道技术往往需要客户端-服务器的共同配合,大部分工作任务其实是在客户端完成,很显然Redis支持管道技术,按照官网的意思,Redis的最低版本就考虑了管道技术的支持性设计。
如下图,多个连续的incr指令,使用pipeline(管道)后,多个连续的incr指令只会花费一次网络来回开销,这个开销会随着n数值的增大,大幅减少网络io开销,从而提升整体服务的性能。管道技术优化的是网络传输的耗时时间。
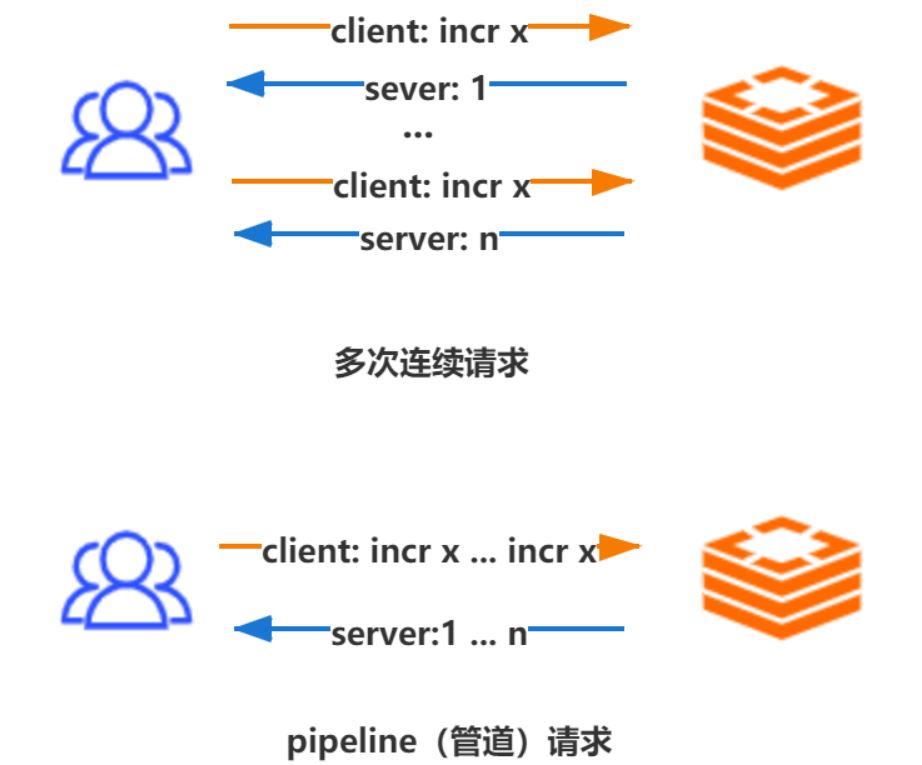
总结:使用管道技术可以解决多个命令执行时的网络等待,它是把多个命令整合到一起发送给服务器端处理之后统一返回给客户端,这样就免去了每条命令执行后都要等待的情况,从而有效地提高了程序的执行效率,但使用管道技术也要注意避免发送的命令过大,或管道内的数据太多而导致的网络阻塞。
适用场景
如果出现集中大批量的请求时,因为每个请求都要经历先请求再响应的过程,这就会造成网络资源浪费,此时就需要管道技术来把所有的命令整合一次发给服务端,再一次响应给客户端,这样就能大大的提升了 Redis 的响应速度。
要求实时性也没那么高,但是最求高性能,这时候用 pipeline 最好了。
benchmark压测pipeline
使用Redis提供的benchmark对Redis进行性能测试,
如过你是Windows下的Redis,在安装目录下有个redis-benchmark.exe,进入cmd命令模式测试即可。
如果你是在Linux下的redis,在安装目录的src目录下有个redis-benchmark
通过普通方式测试set指令和pipeline方式测试set指令,可以看到Redis服务不同的QPS:
普通set方式,Redis QPS 大概在5.3万左右
当使用pipeline set时,随着管道内并行请求数量的增加,Redis QPS可以达到100万以上
代码测试-python: StrictRedis
#引入模块
#这个模块中提供了StrictRedis对象,⽤于连接redis服务器,并按照不同类型提供 了不同⽅法,进⾏交互操作
from redis import StrictRedis
我们使用 StrictRedis客户端提供的 Pipeline 对象来实现管道技术。首先先获取 Pipeline 对象,再为 Pipeline 对象设置需要执行的命令,最后再使用excute() 方法来统一执行这些命令,代码如下:
redis_cli = StrictRedis(host=”xx”, port=xx, password=”xx”, db=xx, decode_responses=True)
import time
def main():
t1 = time.time()
pipe = redis_cli.pipeline()
num = 1
for i in range(100):
pipe.set(“name_” + str(num), num)
pipe.delete(“name_” + str(num))
num += 1
pipe.execute()
t2 = time.time()
print(t2-t1)
接下来我们用普通的命令执行此循环,看下程序的执行时间,代码如下:
t1 = time.time()
num = 10000
for i in range(100):
redis_cli.set(“test_” + str(num), num)
redis_cli.delete(“test_” + str(num))
num += 10
t2 = time.time()
print(t2 – t1)
从结果可以看出,管道的执行时间是0.165秒,而普通命令执行时间是9.09秒,管道技术要比普通的执行快了 56 倍。
代码测试-java:Jedis使用pipeline
package com.liziba.redis;
import redis.clients.jedis.Pipeline;
import java.io.IOException;
public class PipelineTest {
public static void main(String[] args) throws IOException {
Jedis client = new Jedis(“127.0.0.1”, 6379);
long startPipe = System.currentTimeMillis();
Pipeline pipe = client.pipelined();
pipe.multi();
for (int i = 0; i < 100000; i++) {
pipe.set(“pipe” + i, i + “” );
}
pipe.exec();
pipe.close();
long endPipe = System.currentTimeMillis();
System.out.println(“pipeline set cost time : ” + (endPipe – startPipe) + “ms”);
for (int i = 0; i < 100000; i++) {
client.set(“normal” + i, i + “”);
}
System.out.println(“normal set cost time : ” + (System.currentTimeMillis() – endPipe)+ “ms”);
}
}
pipeline注意事项
管道技术虽然有它的优势,但在使用时还需注意以下几个细节:
- 每次pipeline携带数量不推荐过大,否则会影响网络性能
- 如果管道的数据过多可能会导致客户端的等待时间过长,导致网络阻塞
- 发送的命令数量不会被限制,但输入缓存区也就是命令的最大存储体积为 1GB,当发送的命令超过此限制时,命令不会被执行,并且会被 Redis 服务器端断开此链接
- pipeline每次只能作用在一个Redis节点上
- 部分客户端自己本身也有缓存区大小的设置,如果管道命令没有没执行或者是执行不完整,可以排查此情况
参考资料
分布式缓存Redis之Pipeline(管道)
URL: https://blog.csdn.net/u011489043/article/details/78769428
【推荐】Redis精通系列——Pipeline(管道)
参考URL: https://blog.csdn.net/qq_41125219/article/details/120298689
Redis的批量操作是什么?怎么实现的延时队列?以及订阅模式、LRU
参考URL: https://baijiahao.baidu.com/s?id=1687918953043523907
到此这篇关于redis批量操作pipeline管道的文章就介绍到这了,更多相关redis批量操作内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
