
MongoDB聚合分组取第一条记录的案例与实现方法
前言
今天开发同学向我们提了一个紧急的需求,从集合mt_resources_access_log中,根据字段refererDomain分组,取分组中最近一笔插入的数据,然后将这些符合条件的数据导入到集合mt_resources_access_log_new中。
接到这个需求,还是有些心虚的,原因有二,一是,业务需要,时间紧;二是,实现这个功能MongoDB聚合感觉有些复杂,聚合要走好多步。
数据记录格式如下:
记录1
{
“_id” : ObjectId(“5c1e23eaa66bf62c0c390afb”),
“_class” : “C1”,
“resourceUrl” : “/static/js/p.js”,
“refererDomain” : “1234”,
“resourceType” : “static_resource”,
“ip” : “17.17.13.13”,
“createTime” : ISODate(“2018-12-22T19:45:46.015+08:00”),
“disabled” : 0
}
记录2
{
“_id” : ObjectId(“5c1e23eaa66bf62c0c390afb”),
“_class” : “C1”,
“resourceUrl” : “/static/js/p.js”,
“refererDomain” : “1234”,
“resourceType” : “Dome_resource”,
“ip” : “17.17.13.14”,
“createTime” : ISODate(“2018-12-21T19:45:46.015+08:00”),
“disabled” : 0
}
记录3
{
“_id” : ObjectId(“5c1e23eaa66bf62c0c390afb”),
“_class” : “C2”,
“resourceUrl” : “/static/js/p.js”,
“refererDomain” : “1235”,
“resourceType” : “static_resource”,
“ip” : “17.17.13.13”,
“createTime” : ISODate(“2018-12-20T19:45:46.015+08:00”),
“disabled” : 0
}
记录4
{
“_id” : ObjectId(“5c1e23eaa66bf62c0c390afb”),
“_class” : “C2”,
“resourceUrl” : “/static/js/p.js”,
“refererDomain” : “1235”,
“resourceType” : “Dome_resource”,
“ip” : “17.17.13.13”,
“createTime” : ISODate(“2018-12-20T19:45:46.015+08:00”),
“disabled” : 0
}
以上是我们的4条记录,类似的记录文档有1500W。
因为情况特殊,业务发版需要这些数据。催的比较急,而 通过 聚合 框架aggregate,短时间有没有思路, 所以,当时就想着尝试采用其他方案。
最后,问题处理方案如下。
Step 1 通过聚合框架 根据条件要求先分组,并将新生成的数据输出到集合mt_resources_access_log20190122 中(共产生95笔数据);
实现代码如下:
db.log_resources_access_collect.aggregate(
[
{ $group: { _id: “$refererDomain” } },
{ $out : “mt_resources_access_log20190122” }
]
)
Step 2 通过2次 forEach操作,循环处理 mt_resources_access_log20190122和mt_resources_access_log的数据。
代码解释,处理的逻辑为,循环逐笔取出mt_resources_access_log20190122的数据(共95笔),每笔逐行加工处理,处理的逻辑主要是 根据自己的_id字段数据(此字段来自mt_resources_access_log聚合前的refererDomain字段), 去和 mt_resources_access_log的字段 refererDomain比对,查询出符合此条件的数据,并且是按_id 倒序,仅取一笔,最后将Join刷选后的数据Insert到集合mt_resources_access_log_new。
新集合也是95笔数据。
大家不用担心性能,查询语句在1S内实现了结果查询。
db.mt_resources_access_log20190122.find({}).forEach(
function(x) {
db.mt_resources_access_log.find({ “refererDomain”: x._id }).sort({ _id: -1 }).limit(1).forEach(
function(y) {
db.mt_resources_access_log_new.insert(y)
}
)
}
)
Step 3 查询验证新产生的集合mt_resources_access_log_new,结果符合业务要求。
刷选前集合mt_resources_access_log的数据量为1500多W。
刷选后产生新的集合mt_resources_access_log_new 数据量为95笔。
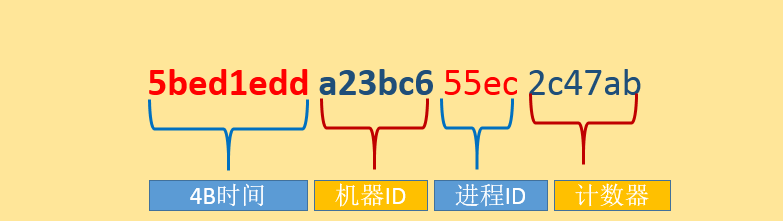
注意:根据时间排序的要求,因为部分文档没有createTime字段类型,且 createTime字段上没有创建索引,所以未了符合按时间排序我们采用了sort({_id:1})的变通方法,因为_id 还有时间的意义。下面的内容为MongoDB对应_id 的相关知识。
最重要的是前4个字节包含着标准的Unix时间戳。后面3个字节是机器ID,紧接着是2个字节的进程ID。最后3个字节存储的是进程本地计数器。计数器可以保证同一个进程和同一时刻内不会重复。
总结
本篇文章到此结束,如果您有相关技术方面疑问可以联系我们技术人员远程解决,感谢大家支持本站!
