
一文了解MySQL二级索引的查询过程
前言
聚簇索引就是innodb默认创建的基于主键的索引结构,而且表里的数据就是直接放在聚簇索引里,作为叶节点的数据页:
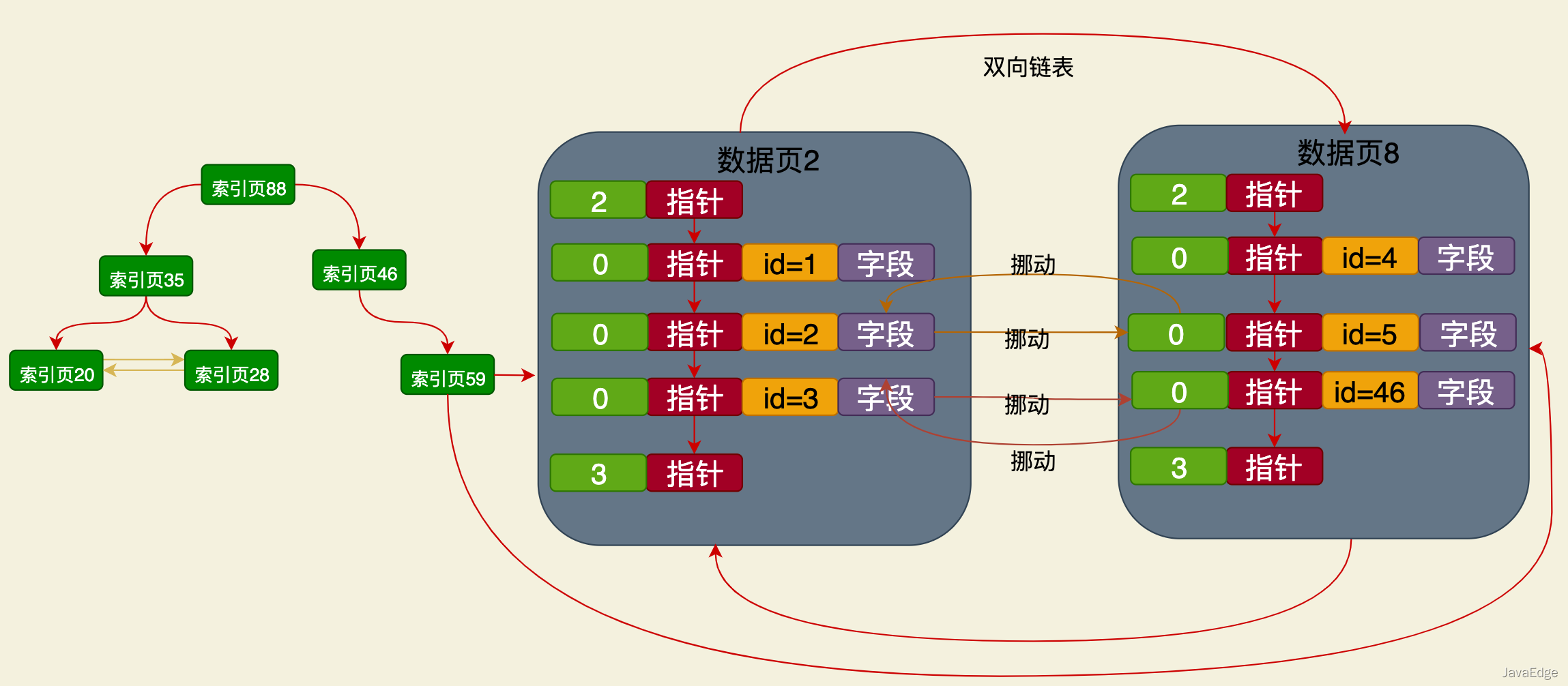
基于主键的数据搜索:从聚簇索引的根节点开始进行二分查找,一路找到对应数据页,基于页目录就直接定位到主键目标数据。
若想对其它字段建立索引,甚至是基于多个字段建立联合索引,此时索引结构又是咋样?
假设对其他字段建立索引,如name、age之类,都是一样原理。比如你插入数据时:
- 把完整数据插入聚簇索引的叶节点的数据页,同时维护好聚簇索引
- 为你其他字段建立的索引,重新再建立一颗B+树
比如你基于name字段建立了一个索引,当插入数据时,就会重新搞一颗B+树,B+树的叶节点也是数据页,但该数据页里仅放主键字段和name字段:
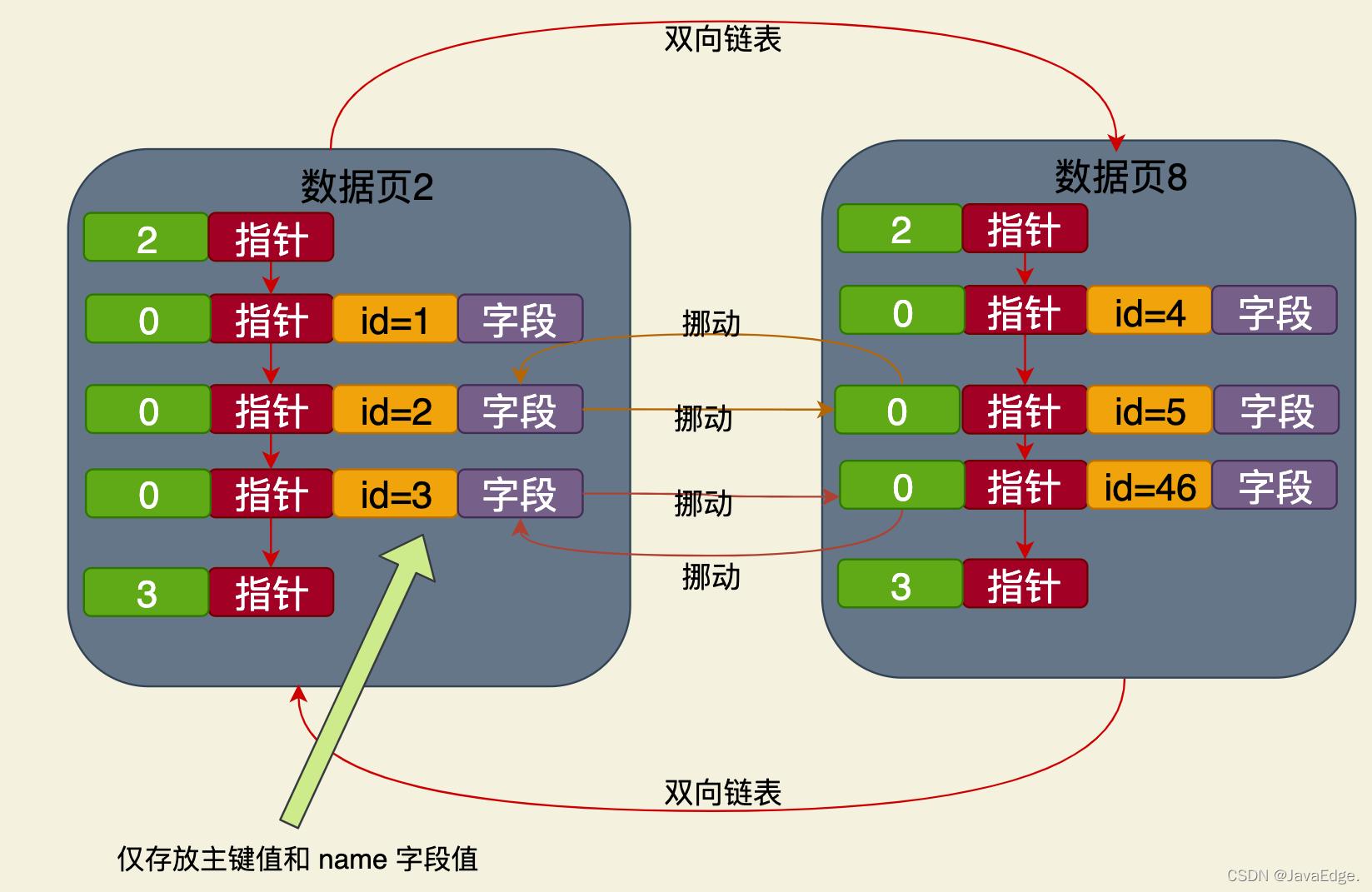
这是独立于聚簇索引之外的另一个name字段的B+索引树,其叶节点的数据页仅存放主键和name字段值。
整体排序规则都跟聚簇索引按照主键的排序规则是一样,即:
- 叶节点的数据页中的name值都是排序的
- 下一个数据页里的name字段值都>上一个数据页里的name字段值
name字段的索引B+树也会构建多层级的索引页,索引页里存放:
- 下一层的页号
- 最小name字段值,根据name字段值排序。
所以若你根据name字段查数据,过程也一样,从name索引树的根节点开始,一层一层往下找,一直找到叶节点的数据页,定位到name字段值对应的主键值。
然后针对
这种语句,先根据name值在name索引树里找,找到叶节点,也仅能找到对应主键值,而找不到这行数据的所有字段。
所以还需回表:还需根据主键值,再到聚簇索引里从根节点开始,找到叶节点的数据页,定位到主键值对应的完整数据行,此时才能把select *要的全部字段值都取出。
联合索引
比如name+age,运行流程同理,建立一个独立的B+树,叶节点的数据页存放id+name+age后,默认按name排序,name一样就按age排,不同数据页之间的name+age值的排序也如此。
然后这个name+age的联合索引的B+树的索引页存放:
- 下一层节点的页号
- 最小的name+age的值
所以当你根据name+age搜索时,就会走name+age联合索引树,搜索到主键,再根据主键到聚簇索引里去搜索。
总结
本篇文章到此结束,如果您有相关技术方面疑问可以联系我们技术人员远程解决,感谢大家支持本站!
在数据页里更新数据维护你所有的索引
到此这篇关于MySQL二级索引查询过程的文章就介绍到这了,更多相关MySQL二级索引查询过程内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
