
MySQL的InnoDB存储引擎的数据页结构详解
1 InnoDB页的概念
InnoDB是一个将表中的数据存储在磁盘上的存储引擎,即使我们关闭并重启服务器,数据还是存在。而真正处理数据的过程发生在内存中,所以需要把磁盘中的数据加载到内存中,所以需要把磁盘中的数据加载到内存中。如果处理写入和修改请求,还需要将内存中的内容刷新到磁盘上。而我们知道读写磁盘的速度非常慢,与读写内存差了几个数量级。当我们想从表中获取某些记录时,InnoDB存储引擎需要一条一条的把记录从磁盘上读出来么?不,那样会慢死,InnoDB采取的方式是,将数据划分为若干个页,以页作为磁盘和内存之间交互的基本单位。InnoDB中页的大小一般为16KB。也就是在一般情况下,一次最少从磁盘中读取16KB的内容到内存中,一次最少把内存中的16KB内容刷新到磁盘中。
2 数据页的结构
存放表中记录的叫索引页也叫数据页,数据页代表的这块16KB大小的存储空间可以划分为多个部分,不同部分有不同功能。
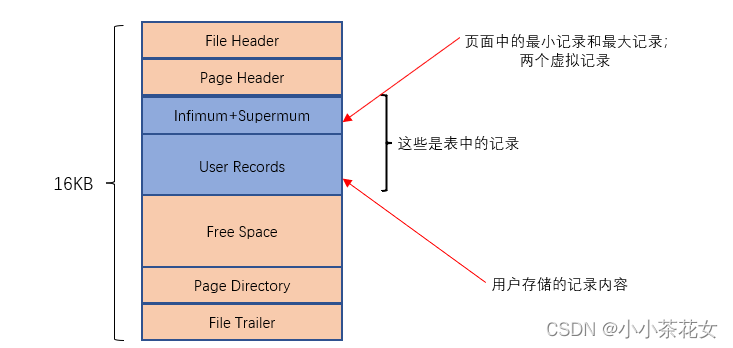
我们自己存储的记录会按照指定的行格式存储到User Records部分,但是一开始生成页的时候,其实并没有User Records部分,每当插入一条记录时,都会从Free Space部分申请一个记录大小的空间,并将这个空间划分到User Records部分。当Free Records部分的空间全部被User Records部分替代掉之后,也就意味着这个页被用完了,此时如果还有新的记录插入,就需要去申请页了。
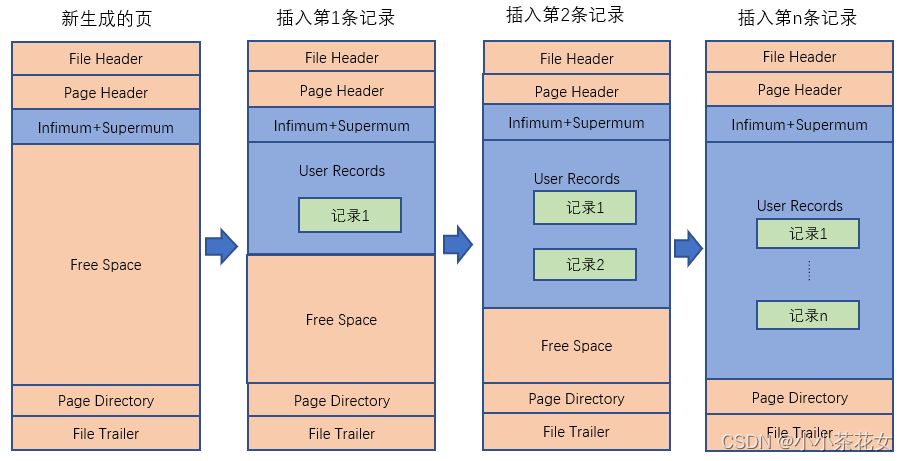
3 记录在页中的存储
假如向page_demo表中插入4条记录,那么这4条记录的存储方式为:
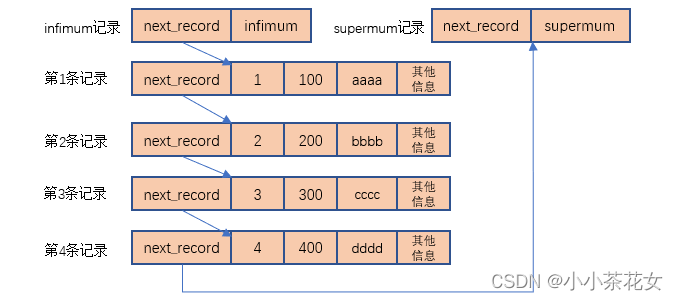
无论向页中插入了多少条记录,InnoDB规定,任何用户记录都比infimum记录大,任何用户记录都不supermum小。
通过记录的存储方式可以看到,记录按照主键从小到大的顺序形成了一个单向链表,通过一条记录可以找到它的下一条记录,下一条记录指的并不是插入顺序中的下一条记录,而是按照主键值由小到大的顺序排列的下一条记录,而且规定infimum记录的下一条记录就是本页中主键值最小的用户记录,本页中主键值最大的用户记录的下一条记录就是supermum记录,supermum记录是单向链表中的最后一个节点。
无论怎么对页中的记录进行增删改查操作,InnoDB始终会维护记录的一个单向链表,链表中的各个节点是按照主键值由小到大的顺序链接起来的。
4 Page Directory页目录
我们知道记录页是按照主键值由小到大的顺序串联成了单向链表,如果想根据主键值查找页中的某条记录,该咋办呢?比如下面的查询语句:
最笨的方法就是从Infimum记录开始,沿着单向链表一直往后找,而且在找的时候可以投机取巧,因为链表中各个记录的值是按照从小到大的顺序排列的,所以当链表中的某个节点记录的主键值大于想要查找的主键值时,就可以停止查找了。
当页中存储的记录数量比较少时,这种方法用起来没有啥问题,但是,如果一个页中存储了非常多的记录,遍历操作对性能来说还是有损耗的,所以遍历查找是一个笨方法,为此InnoDB设计了Page Directory页目录。
(1) 将所有正常的记录(包括infinmum和supermum记录)划分为几个组。InnoDB对每个分组的条数是有规定的,infimum记录所在的分组只能有一条记录,supermum记录所在的分组拥有的记录数只能在18条之间,剩下的分组中记录的条数范围只能在48之间。
(2) 将每个组中最后一条记录在页面中的地址偏移量单独提取出来按顺序存储到靠近页尾部的地方,这个地方就是Page Directory。
比如,现在page_demo有6条记录,InnoDB会把他们分成2个组,第一组只有一个infimum记录,第二组是剩余的5条记录,2个组就对应着两个槽,每个槽存放着每个组中最大的那条记录在页面中的地址偏移量。

由于现在page_demo表中的记录太少,无法掩饰在添加页目录之后是如何加快查找速度的,所以再往page_demo表中添加一些记录。
values(1,100,’aaaa’),(2,200,’bbbb’),(3,300,’cccc’),(4,400,’dddd’),(5,500,’eeee’),(6,600,’ffff’),(7,700,’gggg’),(8,800,’hhhh’),(9,900,’iiii’),(10,1000,’jjjj’),(11,1100,’kkkk’),(12,1200,’llll’),(13,1300,’mmmm’),(14,1400,’nnnn’),(15,1500,’oooo’),
(16,1600,’pppp’)
现在页中就一共有18条记录了(包括infimum记录和supermum记录),这些记录被分成了5个组,因为各个槽之间是挨着的,而且他们代表的记录的主键值都是从小到大排序的,所以可以使用二分法来快速查找。5个槽的编号跟别为0,1,2,3,4,所以初始情况下最低的槽就是low=0,最高的槽就是high=4,假如我们想要寻找主键值为6的记录,过程就是这样的:
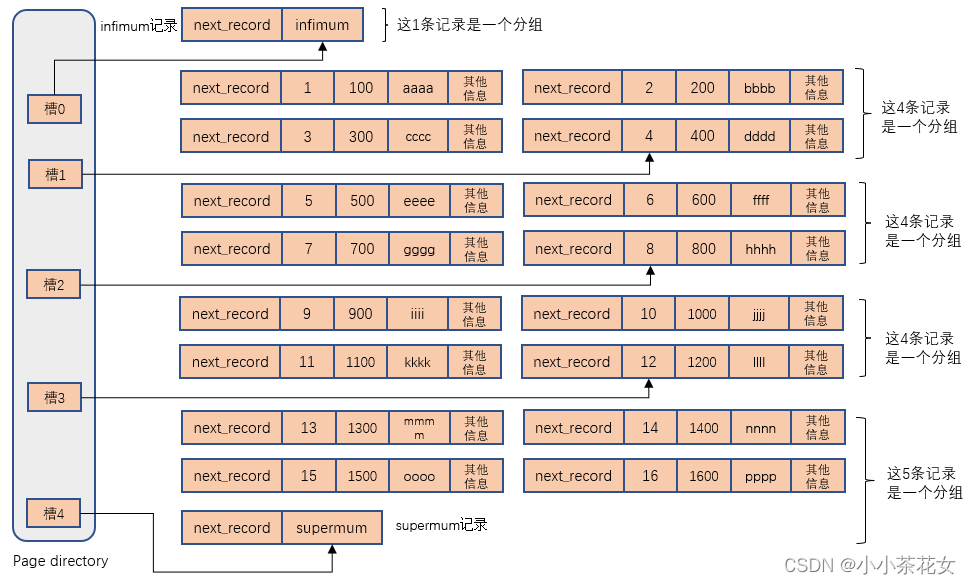
(1) 计算中间槽的位置:(0+4)/2=2,查看槽2对应记录的主键值8;又因为8>6,所以设置high=2,low保持不变。
(2) 重新计算中间槽的位置:(0+2)/2=1,查看槽1对应的记录的主键值为4,又因为4<6,所以设置low=1,high保持不变。
(3) 因为high-low=1,所以主键值为6的记录在槽2对应的组中,此时需要找到槽2所在分组中主键值最小的那条记录,然后沿着单向链表遍历槽2中的记录。
综上所述,在一个数据页中查找指定主键值的记录时,过程分为2步:
(1) 通过二分法确定该记录所在分组对应的槽,然后找到该槽所在分组中主键值最小的那条记录。
(2) 通过记录的next_record属性遍历该槽所在分组中的各个记录。
5 File Header文件头部
InnoDB是以页为单位存放数据的,有时在存放某种类型的数据时,占用的空间非常大。InnoDB可能无法一次性为这么多数据分配一个非常大的存储空间,而如果分散到多个不连续的页中进行存储,则需要把这些也关联起来,FIL_PAGE_PREV和FIL_PAGE_NEXT就分别代表本数据页的上一个页和下一个页的页号。这样通过建立一个双向链表就把许许多多的页串联起来了,而无须这些也在物理上真正连着。所以存储记录的数据页其实可以组成一个双向链表。
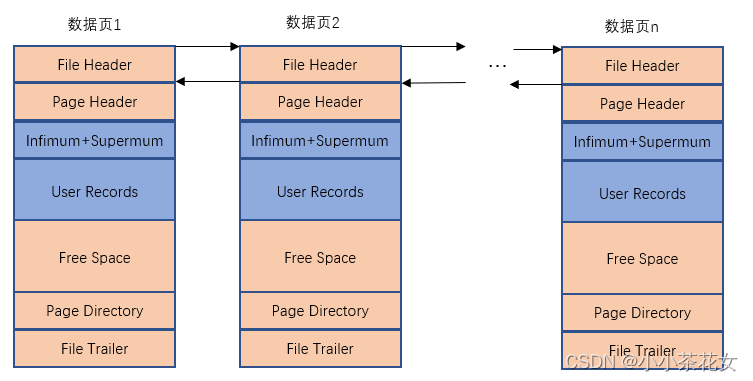
6 InnoDB页和记录的关系
各个数据页可以组成一个双向链表,而每个数据页中的记录会按照主键值从小到大的顺序组成一个单向链表,每个数据页都会为存储在它里面的记录生成一个页目录,在通过主键查找某条记录的时候可以在页目录中使用二分法快速定位到对应的槽,然后遍历该槽对应分组中的记录即可快速找到指定的记录。
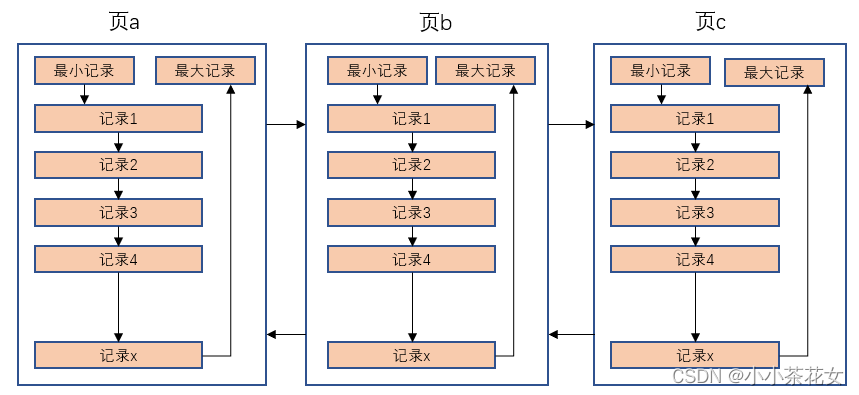
7 没有索引时查找记录
1、在一个页中查找:
假设现在表中的记录较少,所有的记录都可以存放在一个页中,在查找记录时,可以根据搜索条件的不同可以分为两种情况:
(1) 以主键为搜索条件:可以在页目录中使用二分法快速定位到指定的槽,然后遍历该槽对应分组中的记录,即可快速定位到指定的记录。
(2) 以其他列作为搜索条件:对于非主键列的查找就没有那么幸运了,因为在数据页中并没有为非主键列建立所谓的页目录,所以无法通过二分法快速定位相应的槽,在这种情况下只能从Infimum记录开始依次遍历单向链表中的每条记录,然后对比每条记录是否符合搜索条件,这种查找的效率非常低。
2、在很多页中查找:
在很多时候,表中存放的记录都是非常多的,需要用到好多的数据页来存储这些记录。在很多页中查找记录可以分为两个步骤:
(1) 定位到记录所在的页;
(2) 从所在的页内查找相应的记录;
在没有索引的情况下,无论是根据主键列还是其他的列进行查找,由于我们不能快速的定位到记录所在的页,所以只能从第一页沿着双向链表一直往下找。在每一页中我们根据上面说的查找方式去查找指定的记录。因为要遍历所有的数据页,所以这种方式显然是超级耗时的。如果一个表有一亿条记录,使用这种方式去查找记录,估计要到猴年马月才能查到结果,所以就需要一种能高效完成搜索的方法,即索引。
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注的更多内容!
