
MySQL之MyISAM存储引擎的非聚簇索引详解
在InnoDB中索引即数据,也就是聚簇索引的那颗B+树的叶子节点中已经包含了所有完整的用户记录。MyISAM的索引方案虽然也是使用树形结构,但是却将索引和数据分开存储,这种索引也叫非聚簇索引。
c1 int,
c2 int,
c3 char(1),
primary key(c1)
) ROW_FORMAT=COMPACT;
将表中的记录按照记录的插入顺序单独存储在一个文件中,这个文件并不划分为若干个数据页,有多少记录就往这个文件中塞多少个记录,这样一来,我们就可以通过行号快速访问到一条记录。在表中使用MyISAM作为存储引擎时,它的记录在存储空间中的表示如图:
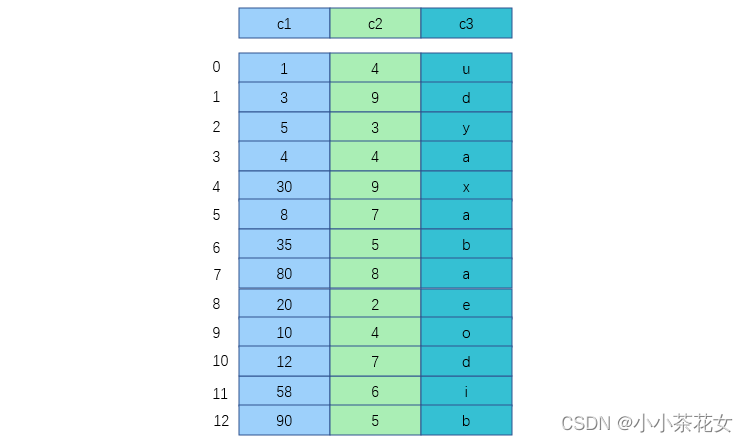
由于在插入数据时并没有刻意按照主键大小排序,所以我们不能再这些数据上使用二分法进行查找,使用MyISAM存储引擎的表会把索引信息单独存储在另外一个文件中,称为索引文件。MyISAM会为表的主键单独创建一个索引,只不过在索引的叶子节点中存储的不是完整的用户记录,而是主键值和行号的组合。也就是先通过索引找到对应的行号,再通过行号去找对应的记录。
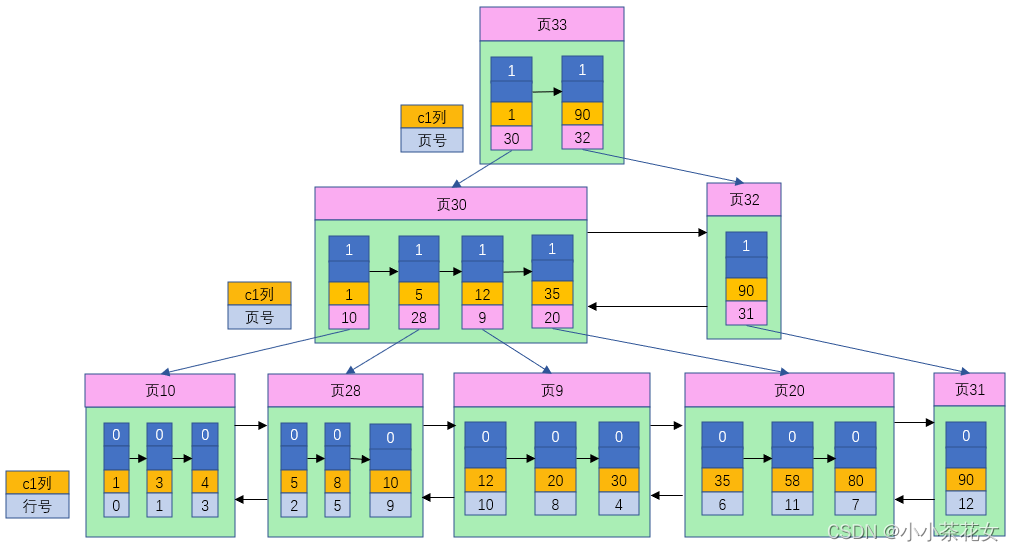
在InnoDB存储引擎中,我们只需要根据主键值对聚簇索引进行一次查找就能找到对应的记录;在MyISAM存储引擎中,需要进行一次回表操作,这也意味着MyISAM中建立的索引相当于全部都是二级索引。
MyISAM会直接在索引叶子节点处存储该条记录在数据文件中的地址偏移量。由此可以看出MyISAM的回表操作时十分快速的,因为它是拿着地址偏移量直接到文件中取数据,而InnoDB是通过获取主键之后再去聚簇索引中找记录,虽然说不慢,但是也比不上直接用地址去访问。
如果有必要,我们也可以为其他列分别建立索引或者建立联合索引,其原理与InnoDB中索引差不多,只不过在叶子节点处存储的是相应的列+行号,这些索引页全部都是二级索引。
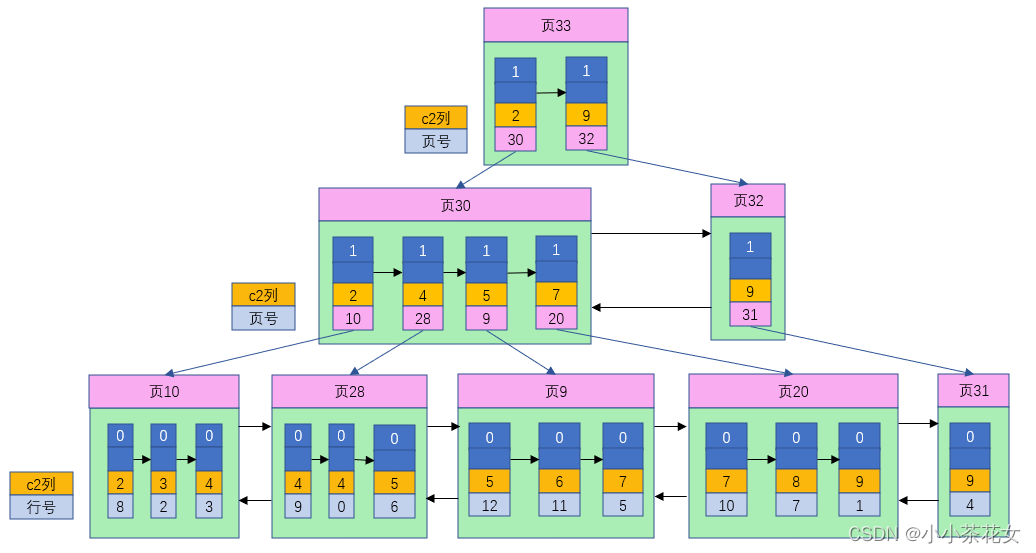
可以看到对于非聚簇索引,不管是以主键为排序规则还是以非主键为排序规则,它的结构都是相同的,即叶子节点存放的都是相应的列+行号。
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注的更多内容!
