
MySQL中explain使用快速查询手册
一. 前言
上一篇整理完了 MySQL 的性能优化方式 , 其中最常用的就是 explain .
这一篇来详细看看 explain 中各个参数的含义和扩展 , 整理出来便于使用时快速查询
二 . explain 使用
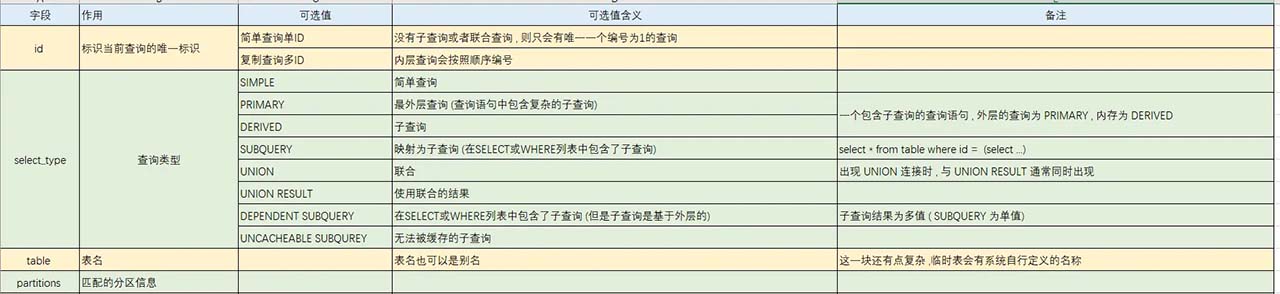
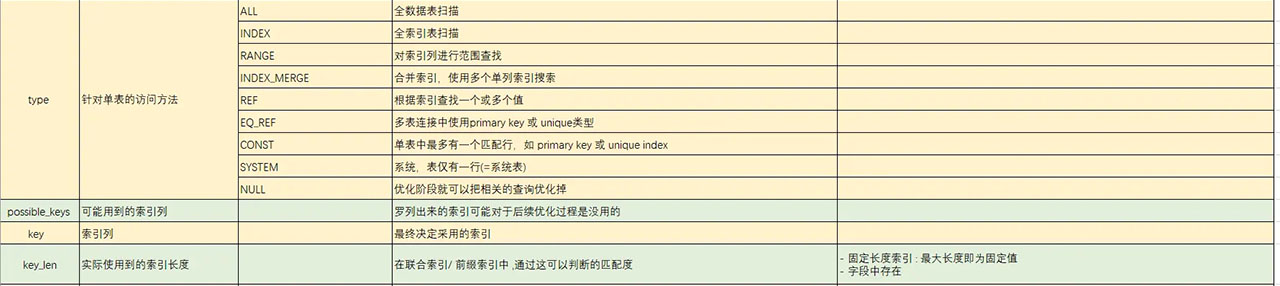
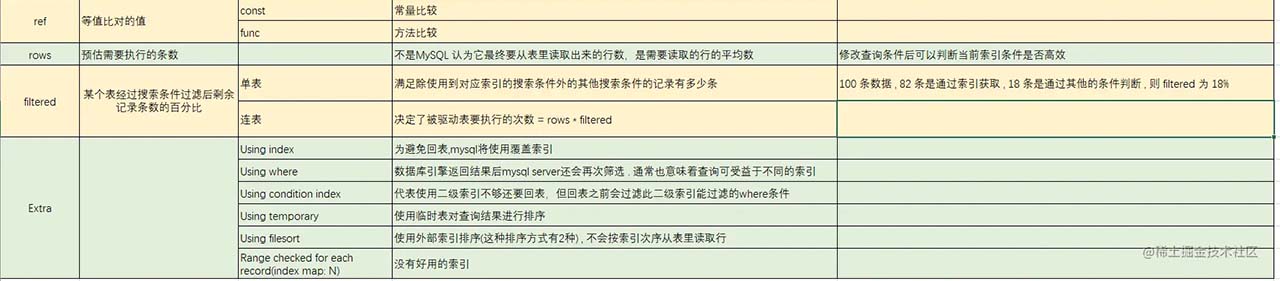
三. 业务实践
在日常实践中 , 我们应该如何使用 explain 提供的查询来判断索引怎么配置呢?
以一个实际业务场景为例 : 首先场景里面的数据分布都很均衡 , 这就导致设置的索引在查询优化器的处理下 , 很难产生最好的效果.
先来看一下表结构 :
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT ‘主键id’,
`user_id` bigint(20) NOT NULL DEFAULT ‘0’ COMMENT ‘会员ID’,
`user_no` bigint(20) NOT NULL DEFAULT ‘0’ COMMENT ‘会员编号’,
`open_id` varchar(128) NOT NULL DEFAULT ” COMMENT ‘外部ID’,
`org_id` varchar(128) NOT NULL DEFAULT ‘0’ COMMENT ‘组织ID’,
`listen_num` int(11) NOT NULL DEFAULT ‘0’ COMMENT ‘记录次数’,
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT ‘创建时间’,
`create_person` varchar(50) NOT NULL DEFAULT ” COMMENT ‘创建人’,
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT ‘更新时间’,
`update_person` varchar(50) NOT NULL DEFAULT ” COMMENT ‘更新人’,
PRIMARY KEY (`id`),
KEY `idx_user_id` (`user_id`),
KEY `idx_org_id_open_id` (`org_id`,`open_id`) USING BTREE,
KEY `idx_create_time` (`create_time`) USING BTREE,
KEY `idx_update_time` (`update_time`) USING BTREE
) COMMENT=’会员记录表’;
需要获取到记录次数 (listen_num) > 0 用户的会员编号 (user_no)- org_id 只有四种数据
(A/B/C/D), 每种数据预计占25% - 30% - 数据是重复修改的关系 ,
修改后会更新 update_time
基础信息
// 2. 不同 org_id 下的记录数
– 1234567890 : 100万
– 9876543210 : 100万
– 8888888888 : 100万
– 6666666666 : 100万
– 其他 : 20万
// 3. 时间周期
> 2022-01
> 2022-12
3.1 以 user_id 为条件进行查找的思路
listen_num 本身没有创建索引 , 以该字段查肯定会走全表 , 优先考虑的思路就是 > user_id 为条件进行有序查询 :

这里看起来好像万事大吉 , 你看索引不是生效了吗 , 只扫描了16行 ,nice!
但是 , 回想一下 B+Tree 的原则 , 在节点里面搜索条件是由小到大有序排列的 , 而带了这个 user_id 处 , 实际上已经快结束了 , 查询优化器理所当然的选择了通过 idx_user_id 进行查询
如果以开始ID做查询条件 ,可以发现实际上索引没有生效 , 而类型也是全表

总结 : 当索引字段遍布整个数据范围 , 且查询很分散的时候 , 在前排序区间的数据可能会放弃使用索引
3.2 以更新时间为查询条件
既然二级索引里面是有序 , 那么以时间作为查询条件是不是最好的 ?
WHERE update_time > “2022-08-03 01:04:55” AND update_time < “2022-09-03 01:04:55” AND listen_num > 0 LIMIT 100

这里看起来就很不错了 , 查询行数和索引都使用的很理想. 但是这里面会有一个致命的问题 , 如果是大批量数据查询 , 那么这里一定会出现深度分页的问题
3.3 简单优化通过 orgId 进行切割
首先数据结构的特点是什么? >> 四个组织分布很平均 , 也就是说如果 org_id 生效 ,我们至少可以只保存四分之一的查询量

初步总结
通过以上三个案例 , 基本上就可以看出 explain 的基本用法
- 通过 type 判断比较的类型
- 通过 key 判断是否使用了自己期望的索引
- 通过 row 判断这个索引的效果
3.4 多索引条件的抉择
要记住的一点是 , 索引并不是我们以为的样子 ,当多个索引同时存在的时候 , MySQL 会根据情况进行选择. 比如 :
WHERE org_id = “1234567890” and update_time > “2022-08-03 01:04:55” AND update_time < “2022-08-04 01:04:55”
and listen_num > 0 LIMIT 100

如果这里把时间周期拉长 , 那么结果也会相应的转变 :
WHERE org_id = “1234567890” and update_time > “2022-08-03 01:04:55” AND update_time < “2022-09-04 01:04:55”
and listen_num > 0 LIMIT 100

3.5 连表查询的关注点
连表查询中主要关注的属性是 filtered , 来实际来看看这个属性 :
EXPLAIN SELECT * FROM user_info as u , org as o WHERE org_id = “123” and u.org_id = o.id

- 在单表时 , filtered 表示索引生效的占比 . 简单来说 ,比例越高,则索引利用率越高
- 在多表时 , 这个表示次表需要查询的行数占比. 也就是被驱动的表剩余的查询次数
四. 深入问题
4.1 explain 的结果能作为最终决策吗?
explain 的结果并不能作为最终决策行为 , explain 是执行计划 , 计划和实际是会存在偏差的, 毕竟 explain 没有真的执行.
哪怕我们最终只需要100行 , 按照 ID 排序的情况下只查几行 , 实际上执行计划的 row 仍然会很庞大.
总结
explain 主要作为参考 , 在实际使用中 , 需要更多的经验思考. 可能最终的结果和explain的不一致.
例如上面的案例 , 按照 explain 的做法 , 用短时间周期最好 ,其次应该是 org_id .
但是根据业务场景 ,我会选择通过 > id 的方式循环查. 一个是业务原因 ,查询的量大 , 上述两种方式都不能避免深度翻页的问题.
到此这篇关于MySQL中explain使用快速查询手册的文章就介绍到这了,更多相关MySQL explain快速查询手册内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
参考 :
<高性能MySQL>
<MySQL 是怎样运行的:从根儿上理解 MySQL>
