
SQL多表联合查询时如何采用字段模糊匹配
[var]
背景:由于业务或是其他不描述的原因的问题导致原有存储的数据发生变动,与现有数据有差别,但还是能勉强看明白数据内容。
要求:实现A表的名称字段和B表的名称字段要模糊匹配。
上图:
假如A表长这样:
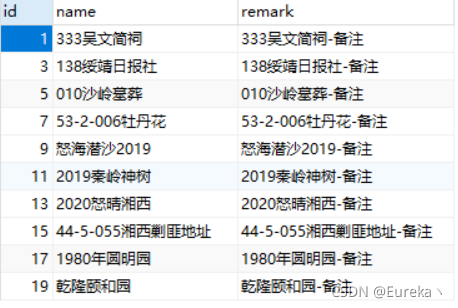
B表长这样:
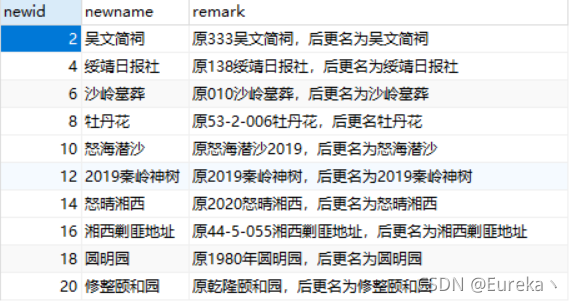
然后我要想变成这样:
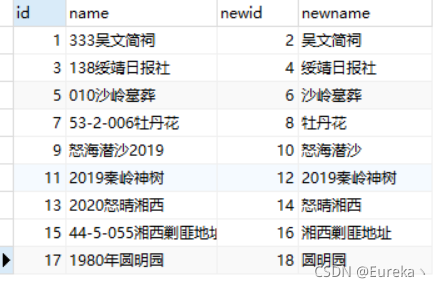
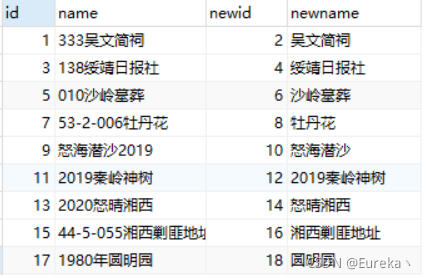
简单说就是在我关联查询两表时,条件字段的取值看起来不一样,但是意思是一样的,应该要把这种数据关联起来。但是SQL里面“=”两边又必须严格相同,所以现在怎么办呢?
[var]
可以采用类似于LIKE模糊查询的办法。
MySQL:
WHERE INSTR(a.`name`,b.newname)>0 OR INSTR(b.newname,a.`name`)>0
或者
WHERE a.`name` LIKE CONCAT(‘%’,b.newname,’%’) OR b.newname LIKE CONCAT(‘%’,a.`name`,’%’)
Oracle:
WHERE a.`name` LIKE ‘%’||b.newname||’%’
SQL Server:
WHERE a.`name` LIKE ‘%’+b.newname+’%’ OR b.newname LIKE ‘%’+a.`name`+’%’
顺便说一下这里用到的字符串拼接功能在三类数据库中的写法:
SQL Server:
Oracle:
或
SELECT CONCAT(‘123′,’456’) FROM dual
MySQL:
Oracle和MySQL中虽然都有CONCAT,但是Oracle中只能拼接2个字符串,所以建议用||的方式,MySQL中的CONCAT则可以拼接多个字符串。
此外,MySQL中的INSTR(STR,SUBSTR)函数,在一个字符串(STR)中搜索指定的字符(SUBSTR),返回发现指定的字符的位置(INDEX)。
- STR—被搜索的字符串;
- SUBSTR—希望搜索的字符串;
结论:在字符串STR里面,字符串SUBSTR出现的第一个位置(INDEX),INDEX是从1开始计算,如果没有找到就直接返回0,没有返回负数的情况。
到这儿,有同学就会发现,你这应用场景也太单一了吧,要是这种:A表被关联字段值为“城乡规划”,B表被关联字段值为“城市规划”;或者A表被关联字段值为“漂亮”,B表被关联字段值为“美丽”。这样的两个字段值也是一个意思,但是用上面的方法就行不通了。
没办法了嘛?
有的。
[var]
你还可以使用NLP的算法来做上面最后提到的那种情况,关于这点,在我之前发表的文章《Word2Vec可视化展示》中已有详细说明,感兴趣的同学可以研究研究。
另外就是,不管哪种办法,总有漏网之鱼,也就是总有你匹配不到的情况,或是匹配错误的情况。所以还需要根据自己的需求、业务以及数据情况,具体问题具体分析,结合各种方法开发代码实现自己想要的功能,做到因地制宜。
那有同学又问了,就没有那种一招打天下的办法了吗?
有的。
[var]
你可以用你的最强大脑去手动处理~~~~~~~~~~
咳咳,我的意思是:就算要手动处理,我们也要减少手动处理的工作量嘛。要不“会急死人的”,真的“会急死人的”!
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
