范围的数据利用Redis缓存技术高效存储指定范围的大量数据(redis 缓存指定)
范围的数据利用Redis缓存技术高效存储指定范围的大量数据
随着互联网的不断发展,数据量的快速增长成为了互联网应用面临的重要问题之一。特别是对于需要处理大量数据的应用,存储和读取效率成为了制约应用性能和响应速度的瓶颈。这时候,使用Redis缓存技术可以很好地解决这个问题。本文将介绍如何利用Redis缓存技术高效存储指定范围的大量数据。
一、Redis缓存技术介绍
Redis是一个内存数据结构存储系统,其底层数据结构包括String、Hash、List、Set、Sorted Set等,提供了类似于数据库的操作。同时,Redis具有多种高效的数据存储方式以及开箱即用的特点,能够快速地存储、读取和维护大量的数据。
二、实现范围数据的Redis缓存
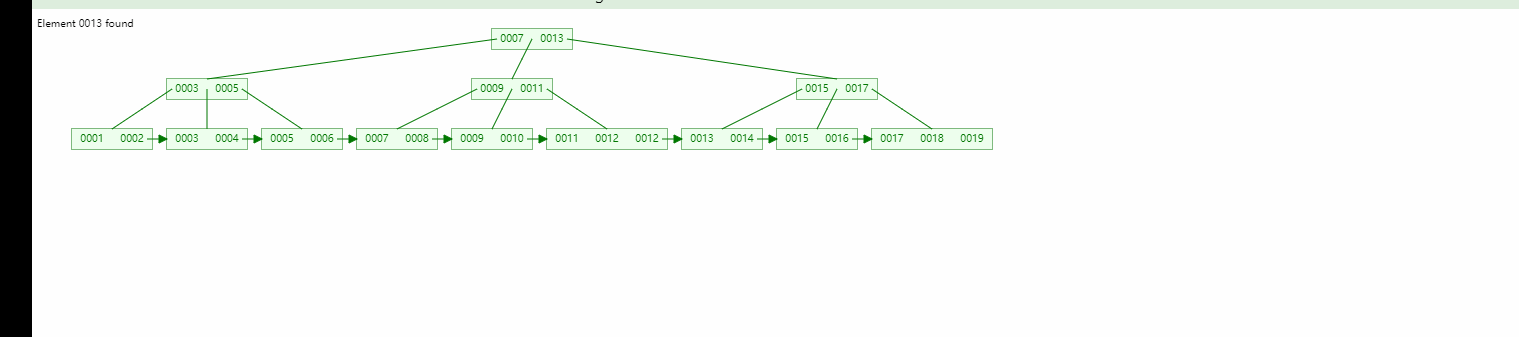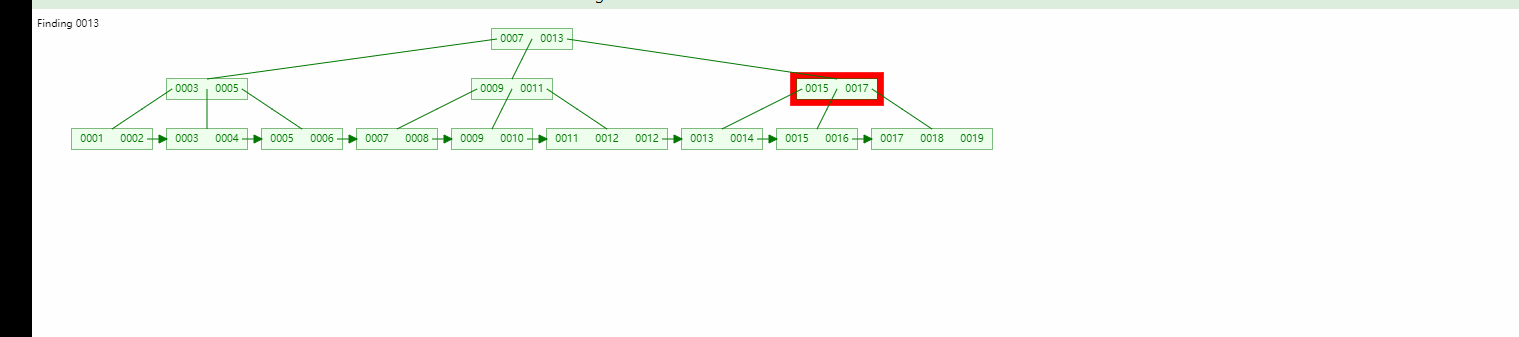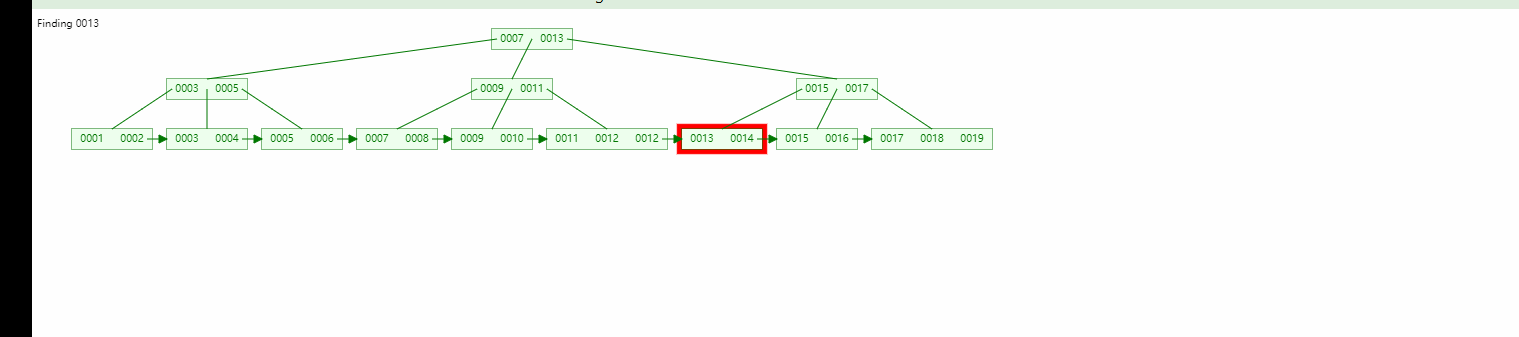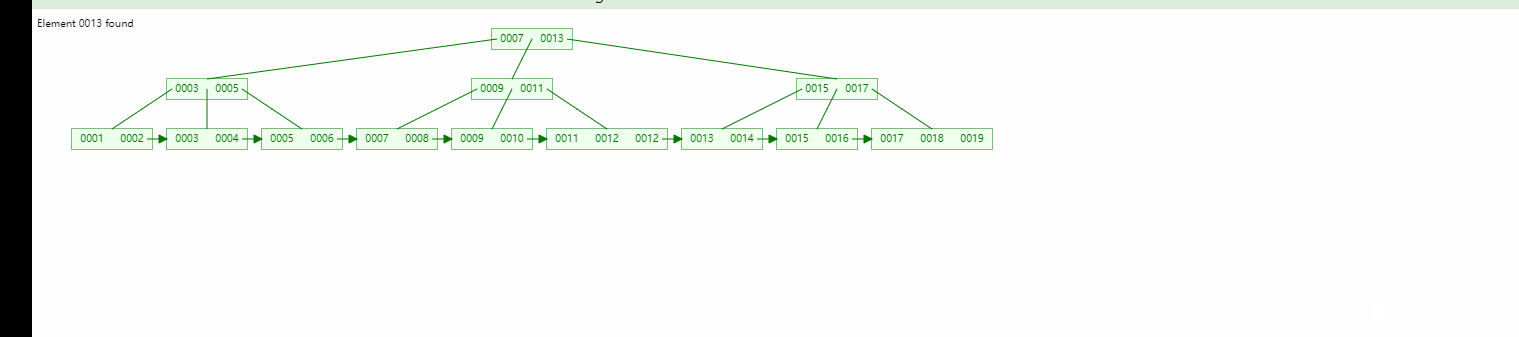
在实际应用中,我们需要对指定范围的大量数据进行存储和读取,并且需要保持高效的响应速度。此时,我们可以使用Redis的有序集合(Sorted Set)和Zrange命令来实现范围数据的存储和读取。
下面是采用Python语言实现范围数据的Redis缓存的示例代码:
“`python
import redis
# 连接Redis数据库
r = redis.Redis(host=’localhost’, port=6379)
# 构造范围数据的有序集合
r.zadd(‘data’, {‘a’: 1, ‘b’: 2, ‘c’: 3, ‘d’: 4, ‘e’: 5, ‘f’: 6, ‘g’: 7, ‘h’: 8, ‘i’: 9, ‘j’: 10})
# 读取指定范围的数据
print(r.zrange(‘data’, 0, 4)) # [‘a’, ‘b’, ‘c’, ‘d’, ‘e’]
在上述示例中,我们首先通过redis.Redis()方法连接了本地的Redis数据库,然后使用r.zadd()方法构造了一个有序集合,集合中包含10个元素。我们使用r.zrange()方法读取了指定范围内的数据,这里我们规定了范围为0~4,即读取有序集合中排名从0到4的元素。
通过使用Redis缓存技术,我们可以快速地存储和读取大量的数据,并且保证了高效的响应速度。在实际应用中,如果我们需要处理更多的数据,可以在有必要时增加Redis实例的数量,从而进一步提高数据处理的效率。
三、总结
范围数据的Redis缓存技术是一种常用的高效数据存储和读取方案。通过利用Redis的有序集合和Zrange命令,我们可以轻松地实现大规模数据的存储和读取,并且保证了高效的响应速度。在实际应用中,我们可以根据实际需求进行适当调整,以达到最佳的性能效果。