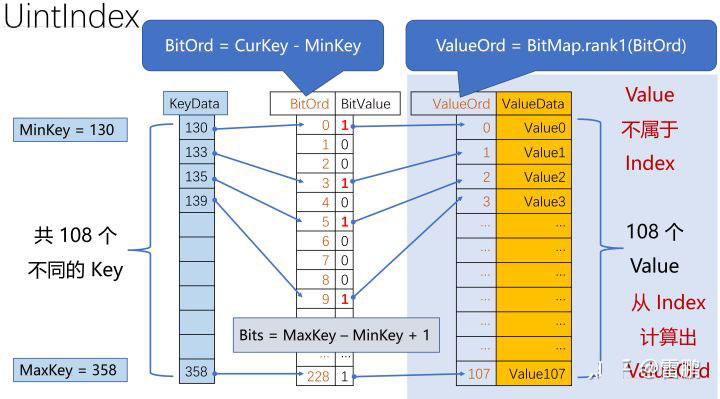
研究Redis集合的实现原理(redis集合实现原理)
Redis集合是一种无序不重复元素,它是存储字符串类型的键值对数据结构。Redis集合的实现原理可以归结为两个核心组件:Hashing和哈希数组跳跃表。
Hashing就是使用某种散列算法将键值映射成一个可以相互比较的整数,这样,对存储在集合中的元素做比较就可以通过比较它们的哈希值来完成。哈希表的底层存储结构是一个数组,其中每个元素都有一个指针指向集合中的一个元素,用户可以使用它来查找或者插入元素。
Redis集合使用一种特殊的数据结构–哈希表来存储集合中的元素,哈希表存储的是键值对,即哈希值对应的集合中的元素,用户可以根据集合中的元素查找它所对应的哈希值,从而获取该元素所在的位置。
Redis集合还使用了另一种特殊的数据结构–哈希跳跃表来高效的查找集合中的元素。哈希跳跃表的结构类似于链表,用户可以根据特定的规则对哈希表进行快速查找。
总结来说,Redis集合的实现原理是通过Hashing与哈希数组跳跃表的结合,可以使我们更方便的实现集合的存储和查询。
以下是示例代码:
// 将元素添加到集合中
SET addElementToSet(SET set, ELEMENT element){
// 获取元素的哈希值
int hash = getHash(element);
// 将元素添加到哈希表中
putIntoHashTable(set, hash, element);
// 将元素添加到哈希跳跃表中
putIntoHashJumpTable(set, hash, element);
return set;
}
// 根据元素的哈希值从集合中查找元素
ELEMENT findElementInSet(SET set, ELEMENT element){
// 获取元素的哈希值
int hash = getHash(element);
// 根据哈希值从哈希表中查找元素
ELEMENT result = findInHashTable(set, hash);
// 如果哈希表中没有,则从哈希跳跃表中查找
if (result == NULL) {
result = findInHashJumpTable(set, hash);
}
return result;
}