
一步步教你 Redis7.0 集群部署的详细步骤
Redis7.0部署集群详细版
集群的架构:集群就是使用网络将若干台计算机联通起来,并提供统一的管理方式,使其对外呈现单机的服务效果
集群的作用:
-
分散单台服务器的访问压力,实现负载均衡
-
分散单台服务器的存储压力,实现可扩展性
-
降低单台服务器宕机带来业务灾难
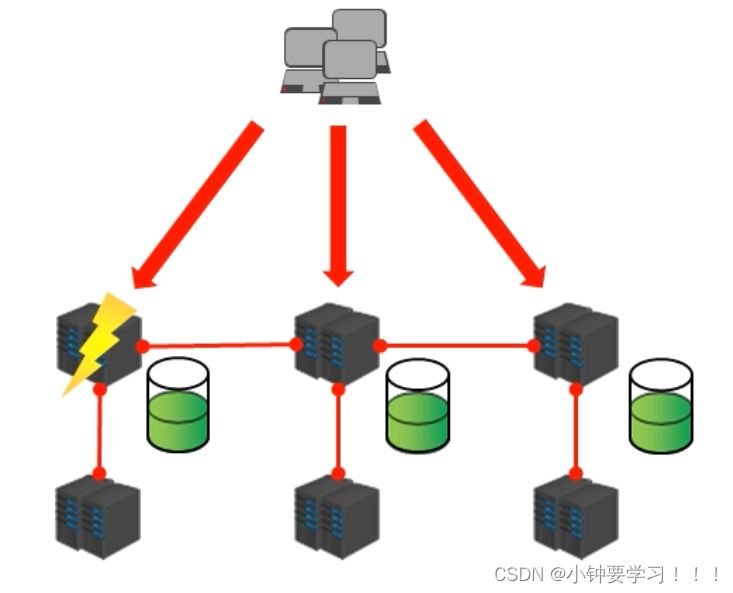
1、Redis集群内部结构设计
数据存储设计
- 通过算法设计,计算出key应该保存的位置
- 将所有的存储空间计划切割成16384份,每台主机保存一部分,每份代表的是一个存储空间,不是一个key的保存空间
- 将key按照计算出的结果放到对应的存储空间
- 增强可扩展性(有新的存储空间加入,官方叫做
槽)
集群内部通讯设计
- 各个数据库相互通信,保存各个库中槽的编号数据
- 一次命中,直接返回
- 一次未命中,告知具体位置
2、cluster集群内部结构搭建
在虚拟机中启动多个窗口进行集群搭建演示

主要命令在
主命令操作客户端执行
修改redis.conf配置文件
添加如下内容
cluster-config-file nodes-6379.conf # cluster配置文件名,该文件属于自动生成,仅用于快速查找文件并查询文件内容
cluster-node-timeout 10000 # 节点服务响应超时时间,用于判定该节点是否下线或切换为从节点
cluster-migration-barrier <count> # master连接的slave最小数量
快速复制5分配置文件并替换里面的端口
全部执行后可以通过
cat指令查看内容确保被修改
启动redis服务集群
redis-server redis-6379.conf
# 在第二个窗口执行6380服务
redis-server redis-6380.conf
# 在第三个窗口执行6381服务
redis-server redis-6381.conf
# 下面的代码依次类推到6385
执行命令查看redis进程和端口
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DPkULwye-1655210548732)(images/image-20220614160930499.jpg)]](https://www.dbs724.com/wp-content/uploads/2022/08/1660314303-98dfaa90be71ba6.jpg)
连接节点
在src目录下查看
redis-trib.rb在高版本中已经将启动操作移动到
redis-cli中启动需要两个下载两个文件分别是
ruby和gem# 下载命令也会将gem一起
yum -y install rubygems
# –cluster-replicas 1 指定集群的内部结构(1代表一个master连接1个slave,2代表一个master连接两个save)
# 后面的连接端口按数量实现master连接哪一个slave,1对1,1对2
redis-cli –cluster create 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 –cluster-replicas 1
执行的结果如下
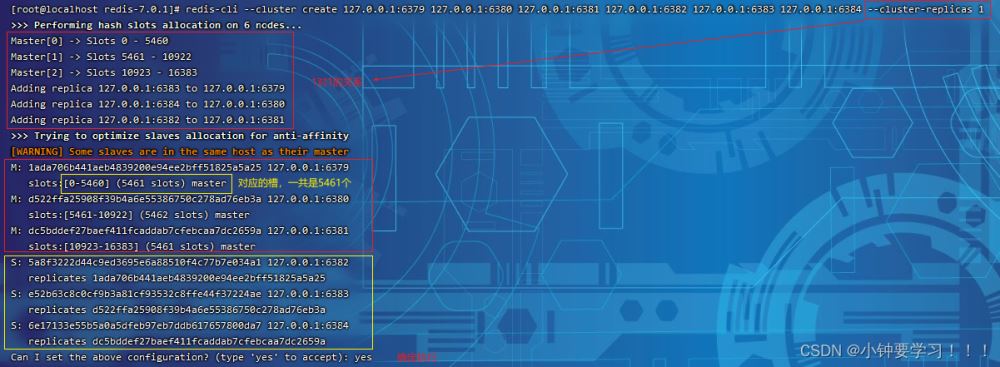
查看配置信息的结果如下
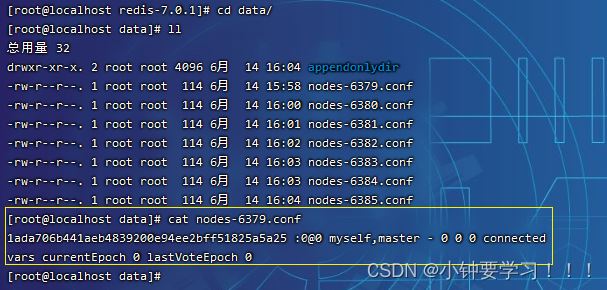
执行yes命令后的信息如下
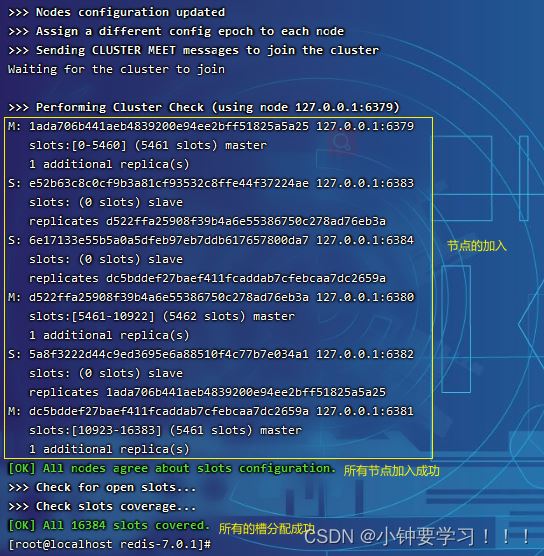
再次查看配置文件的信息,里面记录这所有集群信息
启动客户端存储数据
因为使用了集群部署,所以通过
-c参数可以操作集群,如果不指定的是操作redis命令会提示(error) MOVED 5798 127.0.0.1:6380注意:
-c操作集群
# 创建key,通过返回信息可以知道key存储到6380下了
127.0.0.1:6379> set name 123
-> Redirected to slot [5798] located at 127.0.0.1:6380
OK
指定端口连接客户端
[root@localhost data]# redis-cli -c -p 6382
# 获取key
127.0.0.1:6382> get name
-> Redirected to slot [5798] located at 127.0.0.1:6380
“123”
127.0.0.1:6380>
Cluster节点操作命令
查看集群节点信息
进入一个从节点 redis,切换其主节点
发现一个新节点,新增主节点
忽略一个没有solt的节点
手动故障转移
redis-trib命令
添加节点
删除节点
重新分片
3、主从下线和主从切换
1、模拟从机下线操作
在从机服务器执行
Ctrl + C下载服务
观察连接的主机情况,主机会在10秒内连接不上从机就会标记从机失败,其他集群服务会连接上失败的,其他服务会接收到信息
再次启动从机,主机就会重新连接上从机
如果主机下线了,从机会某槽换位,当主机重新上线的时候,原来的主机就会变成从机
到此这篇关于Redis7.0部署集群的实现步骤的文章就介绍到这了,更多相关Redis7.0部署集群内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
