
详解MongoDB安装使用并实现Python操作数据库的步骤
一、MongoDB介绍
MongoDB 是一个是一个基于分布式文件存储的数据库,介于关系数据库和非关系数据库之间,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
二、安装MongoDB
MongoDB安装很简单,无需下载源文件,可以直接用apt-get命令进行安装。如果网速太差,并且已经下载MongoDB的安装包时,可以离线方式安装,参考Ubuntu下MongoDB安装与使用教程(离线安装方式)。推荐使用apt-get命令进行在线安装,可以避免很多莫名其妙的问题。
以下命令
sudo apt-get install mongodb
可下载安装MongoDB,默认安装的版本是MongoDB 2.6.10,但目前MongoDB已经升级到3.2.8,这里将指导读者通过添加软件源的方式来安装3.2.8版本。
首先打开终端,导入公共key到包管理器,输入以下命令:
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv EA312927
创建MongoDB的文件列表
#仅适用于Ubuntu14.04,输入: echo "deb http://repo.mongodb.org/apt/ubuntu trusty/mongodb-org/3.2 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-3.2.list 更新包管理器,安装MongoDB,输入以下命令: sudo apt-get update sudo apt-get install -y mongodb-org
注意:如果执行“sudo apt-get update”命令后出现如下错误:
···
update completed, but some metadata was ignored due to errors.
E: 无法获得锁 /var/lib/dpkg/lock – open (11: 资源暂时不可用)
E: 无法锁定管理目录(/var/lib/dpkg/),是否有其他进程正占用它?
···
请按照如下方法解决错误,也就是输入以下三条命令:
sudo rm /var/cache/apt/archives/lock sudo rm /var/lib/dpkg/lock sudo apt-get update
运行上面三条命令以后,应该就可以顺利完成apt-get update了。
安装完成MongoDB以后,在终端输入以下命令查看MongoDB版本:
mongo -version
输出版本信息,表明安装成功。
启动和关闭mongodb命令如下:
sudo service mongodb start sudo service mongodb stop
默认设置MongoDB是随Ubuntu启动自动启动的。
输入以下命令查看是否启动成功:
pgrep mongo -l #注意:-l是英文字母l,不是阿拉伯数字1
查看是否启动成功
出现安装错误的解决方案:
输入“sudo service mongodb start”启动mongodb的时候,如果报这个错误:Failed to start mongod.service: Unit not found
请按照如下步骤解决该错误:
(1)使用vim编辑器创建配置文件
sudo vim /etc/systemd/system/mongodb.service
(2)在该配置文件中添加如下内容:
[Unit]
Description=High-performance, schema-free document-oriented database
After=network.target
[Service]
User=mongodb
ExecStart=/usr/bin/mongod –quiet –config /etc/mongod.conf
[Install]
WantedBy=multi-user.target
保存退出vim编辑器。
(3)输入如下命令启动mongodb:
sudo systemctl start mongodb sudo systemctl status mongodb
这时就可以启动成功了。
以后,每次启动和关闭MongoDB,就可以仍然使用如下命令:
sudo service mongodb start sudo service mongodb stop
三、使用MongoDB
shell命令模式
输入如下命令进入MongoDB的shell命令模式:
mongo 或者:sudo mongo
默认连接的数据库是test数据库,在此之前一定要确保你已经启动了MongoDB,否则会出现错误,启动之后运行成功,如下
mongo shell常用操作命令:
数据库相关
show dbs:显示数据库列表
show collections:显示当前数据库中的集合(类似关系数据库中的表table)
show users:显示所有用户
use yourDB:切换当前数据库至yourDB
db.help() :显示数据库操作命令
db.yourCollection.help() :显示集合操作命令,yourCollection是集合名
MongoDB没有创建数据库的命令,如果你想创建一个“School”的数据库,先运行use School命令,之后做一些操作(如:创建聚集集合db.createCollection(‘teacher’)),这样就可以创建一个名叫“School”的数据库。
自动创建school数据库
下面以一个School数据库为例,在School数据库中创建两个集合teacher和student,并对student集合中的数据进行增删改查基本操作(集合Collection相当于关系型数据库中的表table)。
1、切换到School数据库
use School #切换到School数据库。MongoDB 无需预创建School数据库,在使用时会自动创建
2、创建集合Collection
本章节我们为大家介绍如何使用 MongoDB 来创建集合。
MongoDB 中使用 createCollection() 方法来创建集合。
语法格式:
db.createCollection(name, options)
参数说明:

name: 要创建的集合名称
options: 可选参数, 指定有关内存大小及索引的选项
options 可以是如下参数:
在插入文档时,MongoDB 首先检查固定集合的 size 字段,然后检查 max 字段。
实例
在 test 数据库中创建 runoob 集合:
> use test
switched to db test
> db.createCollection(“runoob”)
{ “ok” : 1 }
>
如果要查看已有集合,可以使用 show collections 命令:
> show collections
runoob
system.indexes
下面是带有几个关键参数的 createCollection() 的用法:
创建固定集合 mycol,整个集合空间大小 6142800 KB, 文档最大个数为 10000 个。
> db.createCollection(“mycol”, { capped : true, autoIndexId : true, size : 6142800, max : 10000 } )
{ “ok” : 1 }
>
在 MongoDB 中,你不需要创建集合。当你插入一些文档时,MongoDB 会自动创建集合。
> db.mycol2.insert({“name” : “菜鸟教程”})
> show collections
mycol2
…
##创建一个聚集集合。MongoDB 其实在插入数据的时候,也会自动创建对应的集合,无需预先创建
几种重要的数据类型。
ObjectId
ObjectId 类似唯一主键,可以很快的去生成和排序,包含 12 bytes,含义是:

前 4 个字节表示创建 unix时间戳,格林尼治时间 UTC 时间,比北京时间晚了 8 个小时
接下来的 3 个字节是机器标识码
紧接的两个字节由进程 id 组成 PID
最后三个字节是随机数
MongoDB 中存储的文档必须有一个 _id 键。这个键的值可以是任何类型的,默认是个 ObjectId 对象
由于 ObjectId 中保存了创建的时间戳,所以你不需要为你的文档保存时间戳字段,你可以通过 getTimestamp 函数来获取文档的创建时间:
> var newObject = ObjectId()
> newObject.getTimestamp()
ISODate(“2017-11-25T07:21:10Z”)
ObjectId 转为字符串
> newObject.str
5a1919e63df83ce79df8b38f
字符串
BSON 字符串都是 UTF-8 编码。
时间戳
BSON 有一个特殊的时间戳类型用于 MongoDB 内部使用,与普通的日期类型不相关。 时间戳值是一个 64 位的值。其中:
前32位是一个 time_t 值(与Unix新纪元相差的秒数)
后32位是在某秒中操作的一个递增的序数
在单个 mongod 实例中,时间戳值通常是唯一的。
在复制集中, oplog 有一个 ts 字段。这个字段中的值使用BSON时间戳表示了操作时间。
BSON 时间戳类型主要用于 MongoDB 内部使用。在大多数情况下的应用开发中,你可以使用 BSON 日期类型。
日期
表示当前距离 Unix新纪元(1970年1月1日)的毫秒数。日期类型是有符号的, 负数表示 1970 年之前的日期。
> var mydate1 = new Date() //格林尼治时间
> mydate1
ISODate(“2018-03-04T14:58:51.233Z”)
> typeof mydate1
object
> var mydate2 = ISODate() //格林尼治时间
> mydate2
ISODate(“2018-03-04T15:00:45.479Z”)
> typeof mydate2
object
这样创建的时间是日期类型,可以使用 JS 中的 Date 类型的方法。
返回一个时间类型的字符串:
> var mydate1str = mydate1.toString()
> mydate1str
Sun Mar 04 2018 14:58:51 GMT+0000 (UTC)
> typeof mydate1str
string
或者
> Date()
Sun Mar 04 2018 15:02:59 GMT+0000 (UTC)
1、插入数据
与数据库创建类似,插入数据时也会自动创建集合。
插入数据有两种方式:insert和save。
db.student.insert({_id:1, sname: 'zhangsan', sage: 20}) #_id可选
db.student.save({_id:1, sname: 'zhangsan', sage: 22}) #_id可选
这两种方式,其插入的数据中_id字段均可不写,会自动生成一个唯一的_id来标识本条数据。而insert和save不同之处在于:在手动插入_id字段时,如果_id已经存在,insert不做操作,save做更新操作;如果不加_id字段,两者作用相同点都是插入数据。
insert和save添加的数据其结构是松散的,列属性均不固定,根据添加的数据为准。先定义数据再插入,就可以一次性插入多条数据,
插入多条
运行完以上例子,student 已自动创建,这也说明 MongoDB 不需要预先定义 collection ,在第一次插入数据后,collection 会自动的创建。
2、查找数据
MongoDB 查询文档使用 find() 方法。
find() 方法以非结构化的方式来显示所有文档。
语法
MongoDB 查询数据的语法格式如下:
db.collection.find(query, projection)
query :可选,使用查询操作符指定查询条件
projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
如果你需要以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下:>db.col.find().pretty()
pretty() 方法以格式化的方式来显示所有文档。
除了 find() 方法之外,还有一个 findOne() 方法,它只返回一个文档。
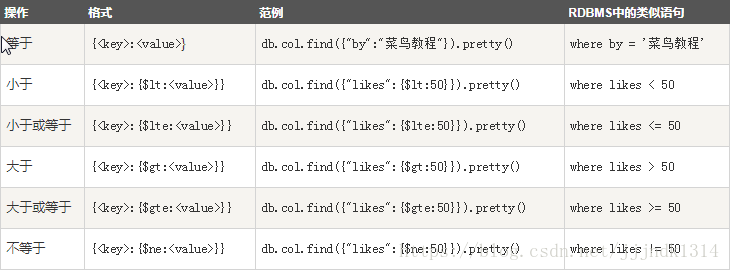
MongoDB 与 RDBMS Where 语句比较
如果你熟悉常规的 SQL 数据,通过下表可以更好的理解 MongoDB 的条件语句查询:
MongoDB AND 条件
MongoDB 的 find() 方法可以传入多个键(key),每个键(key)以逗号隔开,即常规 SQL 的 AND 条件。
语法格式如下:
db.col.find({key1:value1, key2:value2}).pretty()
MongoDB OR 条件
MongoDB OR 条件语句使用了关键字 $or,语法格式如下:
db.col.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()
AND 和 OR 联合使用
以下实例演示了 AND 和 OR 联合使用,类似常规 SQL 语句为: ‘where likes>50 AND (by = ‘菜鸟教程’ OR title = ‘MongoDB 教程’)’
db.col.find({“likes”: {$gt:50}, $or: [{“by”: “菜鸟教程”},{“title”: “MongoDB 教程”}]}).pretty()
3、更新数据
MongoDB 更新文档
MongoDB 使用 update() 和 save() 方法来更新集合中的文档。接下来让我们详细来看下两个函数的应用及其区别。
update() 方法
update() 方法用于更新已存在的文档。语法格式如下:
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
参数说明:
query : update的查询条件,类似sql update查询内where后面的。
update : update的对象和一些更新的操作符(如 set, s e t , inc…)等,也可以理解为sql update查询内set后面的
upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
writeConcern :可选,抛出异常的级别。
实例
我们在集合 col 中插入如下数据:
>db.col.insert({
title: ‘MongoDB 教程’,
description: ‘MongoDB 是一个 Nosql 数据库’,
by: ‘菜鸟教程’,
url: ‘http://www.runoob.com’,
tags: [‘mongodb’, ‘database’, ‘NoSQL’],
likes: 100
})
接着我们通过 update() 方法来更新标题(title):
>db.col.update({‘title’:’MongoDB 教程’},{$set:{‘title’:’MongoDB’}}) ##加$set 用处:仅修改目标行,否则不会保留其他行。
WriteResult({ “nMatched” : 1, “nUpserted” : 0, “nModified” : 1 }) # 输出信息
> db.col.find().pretty()
{
“_id” : ObjectId(“56064f89ade2f21f36b03136”),
“title” : “MongoDB”,
“description” : “MongoDB 是一个 Nosql 数据库”,
“by” : “菜鸟教程”,
“url” : “http://www.runoob.com”,
“tags” : [
“mongodb”,
“database”,
“NoSQL”
],
“likes” : 100
}
>
#可以看到标题(title)由原来的 “MongoDB 教程” 更新为了 “MongoDB”。
以上语句只会修改第一条发现的文档,如果你要修改多条相同的文档,则需要设置 multi 参数为 true。
>db.col.update({‘title’:’MongoDB 教程’},{$set:{‘title’:’MongoDB’}},{multi:true})
save() 方法
save() 方法通过传入的文档来替换已有文档。语法格式如下:
db.collection.save(
<document>,
{
writeConcern: <document>
}
)
参数说明:
document : 文档数据。
writeConcern :可选,抛出异常的级别。
实例
以下实例中我们替换了 _id 为 56064f89ade2f21f36b03136 的文档数据:
>db.col.save({
“_id” : ObjectId(“56064f89ade2f21f36b03136”),
“title” : “MongoDB”,
“description” : “MongoDB 是一个 Nosql 数据库”,
“by” : “Runoob”,
“url” : “http://www.runoob.com”,
“tags” : [
“mongodb”,
“NoSQL”
],
“likes” : 110
})
替换成功后,我们可以通过 find() 命令来查看替换后的数据
>db.col.find().pretty()
{
“_id” : ObjectId(“56064f89ade2f21f36b03136”),
“title” : “MongoDB”,
“description” : “MongoDB 是一个 Nosql 数据库”,
“by” : “Runoob”,
“url” : “http://www.runoob.com”,
“tags” : [
“mongodb”,
“NoSQL”
],
“likes” : 110
}
>
更多实例
只更新第一条记录:
db.col.update( { “count” : { $gt : 1 } } , { $set : { “test2” : “OK”} } );
全部更新:
db.col.update( { “count” : { $gt : 3 } } , { $set : { “test2” : “OK”} },false,true );
只添加第一条:
db.col.update( { “count” : { $gt : 4 } } , { $set : { “test5” : “OK”} },true,false );
全部添加加进去:
db.col.update( { “count” : { $gt : 5 } } , { $set : { “test5” : “OK”} },true,true );
全部更新:
db.col.update( { “count” : { $gt : 15 } } , { $inc : { “count” : 1} },false,true );
只更新第一条记录:
db.col.update( { “count” : { $gt : 10 } } , { $inc : { “count” : 1} },false,false );
4、删除数据
在前面的几个章节中我们已经学习了MongoDB中如何为集合添加数据和更新数据。在本章节中我们将继续学习MongoDB集合的删除。
MongoDB remove()函数是用来移除集合中的数据。
MongoDB数据更新可以使用update()函数。在执行remove()函数前先执行find()命令来判断执行的条件是否正确,这是一个比较好的习惯。
语法
remove() 方法的基本语法格式如下所示:
db.collection.remove(
<query>,
<justOne>
)
如果你的 MongoDB 是 2.6 版本以后的,语法格式如下:
db.collection.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)
参数说明:
query :(可选)删除的文档的条件。
justOne : (可选)如果设为 true 或 1,则只删除一个文档。
writeConcern :(可选)抛出异常的级别。
实例
以下文档我们执行两次插入操作:
>db.col.insert({title: ‘MongoDB 教程’,
description: ‘MongoDB 是一个 Nosql 数据库’,
by: ‘菜鸟教程’,
url: ‘http://www.runoob.com’,
tags: [‘mongodb’, ‘database’, ‘NoSQL’],
likes: 100
})
使用 find() 函数查询数据:
> db.col.find()
{ “_id” : ObjectId(“56066169ade2f21f36b03137”), “title” : “MongoDB 教程”, “description” : “MongoDB 是一个 Nosql 数据库”, “by” : “菜鸟教程”, “url” : “http://www.runoob.com”, “tags” : [ “mongodb”, “database”, “NoSQL” ], “likes” : 100 }
{ “_id” : ObjectId(“5606616dade2f21f36b03138”), “title” : “MongoDB 教程”, “description” : “MongoDB 是一个 Nosql 数据库”, “by” : “菜鸟教程”, “url” : “http://www.runoob.com”, “tags” : [ “mongodb”, “database”, “NoSQL” ], “likes” : 100 }
接下来我们移除 title 为 ‘MongoDB 教程’ 的文档:
>db.col.remove({‘title’:’MongoDB 教程’})
WriteResult({ “nRemoved” : 2 }) # 删除了两条数据
>db.col.find()
…… # 没有数据
如果你只想删除第一条找到的记录可以设置 justOne 为 1,如下所示:
>db.COLLECTION_NAME.remove(DELETION_CRITERIA,1)
如果你想删除所有数据,可以使用以下方式(类似常规 SQL 的 truncate 命令):
>db.col.remove({})
>db.col.find()
>
5、条件运算符
条件操作符用于比较两个表达式并从mongoDB集合中获取数据。
MongoDB中条件操作符有:
(>) 大于 – $gt
(<) 小于 – $lt
(>=) 大于等于 – $gte
(<= ) 小于等于 – $lte
我们使用的数据库名称为”runoob” 我们的集合名称为”col”,以下为我们插入的数据。
为了方便测试,我们可以先使用以下命令清空集合 “col” 的数据:
db.col.remove({})
插入以下数据
>db.col.insert({
title: ‘PHP 教程’,
description: ‘PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言。’,
by: ‘菜鸟教程’,
url: ‘http://www.runoob.com’,
tags: [‘php’],
likes: 200
})
>db.col.insert({title: ‘Java 教程’,
description: ‘Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。’,
by: ‘菜鸟教程’,
url: ‘http://www.runoob.com’,
tags: [‘java’],
likes: 150
})
>db.col.insert({title: ‘MongoDB 教程’,
description: ‘MongoDB 是一个 Nosql 数据库’,
by: ‘菜鸟教程’,
url: ‘http://www.runoob.com’,
tags: [‘mongodb’],
likes: 100
})
使用find()命令查看数据:
db.col.find()
MongoDB (>) 大于操作符 – $gt
如果你想获取 “col” 集合中 “likes” 大于 100 的数据,你可以使用以下命令:
db.col.find({“likes” : {$gt : 100}})
类似于SQL语句:
Select * from col where likes > 100;
输出结果:
> db.col.find({“likes” : {$gt : 100}})
{ “_id” : ObjectId(“56066542ade2f21f36b0313a”), “title” : “PHP 教程”, “description” : “PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言。”, “by” : “菜鸟教程”, “url” : “http://www.runoob.com”, “tags” : [ “php” ], “likes” : 200 }
{ “_id” : ObjectId(“56066549ade2f21f36b0313b”), “title” : “Java 教程”, “description” : “Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。”, “by” : “菜鸟教程”, “url” : “http://www.runoob.com”, “tags” : [ “java” ], “likes” : 150 }
>
MongoDB(>=)大于等于操作符 – $gte
如果你想获取”col”集合中 “likes” 大于等于 100 的数据,你可以使用以下命令:
db.col.find({likes : {$gte : 100}})
类似于SQL语句:
Select * from col where likes >=100;
输出结果:
> db.col.find({likes : {$gte : 100}})
{ “_id” : ObjectId(“56066542ade2f21f36b0313a”), “title” : “PHP 教程”, “description” : “PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言。”, “by” : “菜鸟教程”, “url” : “http://www.runoob.com”, “tags” : [ “php” ], “likes” : 200 }
{ “_id” : ObjectId(“56066549ade2f21f36b0313b”), “title” : “Java 教程”, “description” : “Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。”, “by” : “菜鸟教程”, “url” : “http://www.runoob.com”, “tags” : [ “java” ], “likes” : 150 }
{ “_id” : ObjectId(“5606654fade2f21f36b0313c”), “title” : “MongoDB 教程”, “description” : “MongoDB 是一个 Nosql 数据库”, “by” : “菜鸟教程”, “url” : “http://www.runoob.com”, “tags” : [ “mongodb” ], “likes” : 100 }
>
MongoDB (<) 小于操作符 – $lt
如果你想获取”col”集合中 “likes” 小于 150 的数据,你可以使用以下命令:
db.col.find({likes : {$lt : 150}})
类似于SQL语句:
Select * from col where likes < 150;
输出结果:
> db.col.find({likes : {$lt : 150}})
{ “_id” : ObjectId(“5606654fade2f21f36b0313c”), “title” : “MongoDB 教程”, “description” : “MongoDB 是一个 Nosql 数据库”, “by” : “菜鸟教程”, “url” : “http://www.runoob.com”, “tags” : [ “mongodb” ], “likes” : 100 }
MongoDB (<=) 小于操作符 – $lte
如果你想获取”col”集合中 “likes” 小于等于 150 的数据,你可以使用以下命令:
db.col.find({likes : {$lte : 150}})
类似于SQL语句:
Select * from col where likes <= 150;
输出结果:
> db.col.find({likes : {$lte : 150}})
{ “_id” : ObjectId(“56066549ade2f21f36b0313b”), “title” : “Java 教程”, “description” : “Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。”, “by” : “菜鸟教程”, “url” : “http://www.runoob.com”, “tags” : [ “java” ], “likes” : 150 }
{ “_id” : ObjectId(“5606654fade2f21f36b0313c”), “title” : “MongoDB 教程”, “description” : “MongoDB 是一个 Nosql 数据库”, “by” : “菜鸟教程”, “url” : “http://www.runoob.com”, “tags” : [ “mongodb” ], “likes” : 100 }
MongoDB 使用 (<) 和 (>) 查询 – $lt 和 $gt
如果你想获取”col”集合中 “likes” 大于100,小于 200 的数据,你可以使用以下命令:
db.col.find({likes : {$lt :200, $gt : 100}})
类似于SQL语句:
Select * from col where likes>100 AND likes<200;
输出结果:
> db.col.find({likes : {$lt :200, $gt : 100}})
{ “_id” : ObjectId(“56066549ade2f21f36b0313b”), “title” : “Java 教程”, “description” : “Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。”, “by” : “菜鸟教程”, “url” : “http://www.runoob.com”, “tags” : [ “java” ], “likes” : 150 }
>
6、MongoDB Limit与Skip方法
MongoDB Limit() 方法
如果你需要在MongoDB中读取指定数量的数据记录,可以使用MongoDB的Limit方法,limit()方法接受一个数字参数,该参数指定从MongoDB中读取的记录条数。
语法
limit()方法基本语法如下所示:
db.COLLECTION_NAME.find().limit(NUMBER)
实例
集合 col 中的数据如下:
db.col.find({},{“title”:1,_id:0}).limit(2) # _id:0(投影1:表示显示0:表示隐藏)
{ “title” : “PHP 教程” }
{ “title” : “Java 教程” }
注:如果你们没有指定limit()方法中的参数则显示集合中的所有数据。
MongoDB Skip() 方法
我们除了可以使用limit()方法来读取指定数量的数据外,还可以使用skip()方法来跳过指定数量的数据,skip方法同样接受一个数字参数作为跳过的记录条数。
db.col.find({},{“title”:1,_id:0}).limit(2) # _id:0(投影1:表示显示0:表示隐藏)
{ “title” : “PHP 教程” }
{ “title” : “Java 教程” }
注:如果你们没有指定limit()方法中的参数则显示集合中的所有数据。
7.MongoDB排序
MongoDB sort()方法
在MongoDB中使用使用sort()方法对数据进行排序,sort()方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而-1是用于降序排列。
语法
sort()方法基本语法如下所示:
>db.COLLECTION_NAME.find().sort({KEY:1})
实例
col 集合中的数据如下:
{ “_id” : ObjectId(“56066542ade2f21f36b0313a”), “title” : “PHP 教程”, “description” : “PHP 是一种创建动态交互性站点的强有力的服务器端脚本语言。”, “by” : “菜鸟教程”, “url” : “http://www.runoob.com”, “tags” : [ “php” ], “likes” : 200 }
{ “_id” : ObjectId(“56066549ade2f21f36b0313b”), “title” : “Java 教程”, “description” : “Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。”, “by” : “菜鸟教程”, “url” : “http://www.runoob.com”, “tags” : [ “java” ], “likes” : 150 }
{ “_id” : ObjectId(“5606654fade2f21f36b0313c”), “title” : “MongoDB 教程”, “description” : “MongoDB 是一个 Nosql 数据库”, “by” : “菜鸟教程”, “url” : “http://www.runoob.com”, “tags” : [ “mongodb” ], “likes” : 100 }
以下实例演示了 col 集合中的数据按字段 likes 的降序排列:
>db.col.find({},{“title”:1,_id:0}).sort({“likes”:-1})
{ “title” : “PHP 教程” }
{ “title” : “Java 教程” }
{ “title” : “MongoDB 教程” }
>
8.MongoDB索引
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构
ensureIndex() 方法
MongoDB使用 ensureIndex() 方法来创建索引。
语法
ensureIndex()方法基本语法格式如下所示:
db.COLLECTION_NAME.ensureIndex({KEY:1})
语法中 Key 值为你要创建的索引字段,1为指定按升序创建索引,如果你想按降序来创建索引指定为-1即可。
实例
db.col.ensureIndex({“title”:1})
ensureIndex() 方法中你也可以设置使用多个字段创建索引(关系型数据库中称作复合索引)。
db.col.ensureIndex({“title”:1,”description”:-1})
ensureIndex() 接收可选参数,可选参数列表如下:
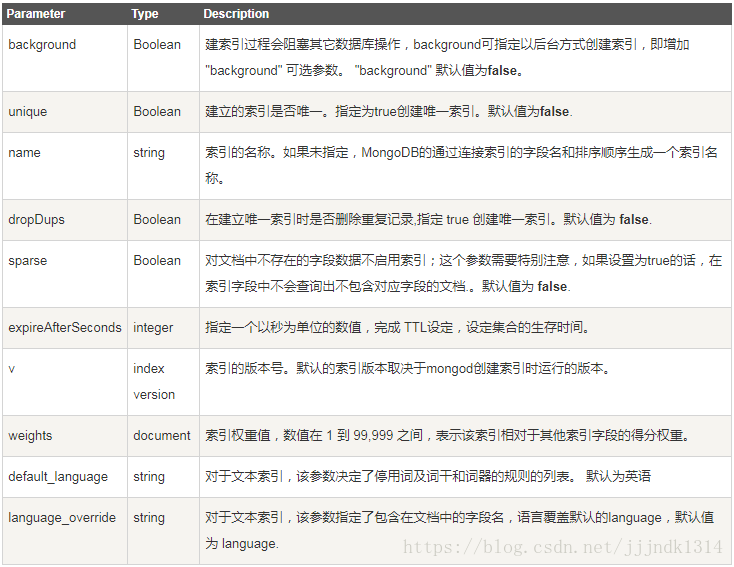
实例在后台创建索引:
db.values.ensureIndex({open: 1, close: 1}, {background: true})
通过在创建索引时加background:true 的选项,让创建工作在后台执行
8.MongoDB 聚合
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)。
aggregate() 方法
MongoDB中聚合的方法使用aggregate()。
语法
aggregate() 方法的基本语法格式如下所示:
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
实例
集合中的数据如下:
{
_id: ObjectId(7df78ad8902c)
title: ‘MongoDB Overview’,
description: ‘MongoDB is no sql database’,
by_user: ‘runoob.com’,
url: ‘http://www.runoob.com’,
tags: [‘mongodb’, ‘database’, ‘NoSQL’],
likes: 100
},
{
_id: ObjectId(7df78ad8902d)
title: ‘NoSQL Overview’,
description: ‘No sql database is very fast’,
by_user: ‘runoob.com’,
url: ‘http://www.runoob.com’,
tags: [‘mongodb’, ‘database’, ‘NoSQL’],
likes: 10
},
{
_id: ObjectId(7df78ad8902e)
title: ‘Neo4j Overview’,
description: ‘Neo4j is no sql database’,
by_user: ‘Neo4j’,
url: ‘http://www.neo4j.com’,
tags: [‘neo4j’, ‘database’, ‘NoSQL’],
likes: 750
},
现在我们通过以上集合计算每个作者所写的文章数,使用aggregate()计算结果如下:
## _id 指定根据那个属性分组
db.mycol.aggregate([{$group : {_id : “$by_user”, num_tutorial : {$sum : 1}}}])
{
“result” : [
{
“_id” : “runoob.com”,
“num_tutorial” : 2
},
{
“_id” : “Neo4j”,
“num_tutorial” : 1
}
],
“ok” : 1
}
以上实例类似sql语句: select by_user, count(*) from mycol group by by_user
在上面的例子中,我们通过字段by_user字段对数据进行分组,并计算by_user字段相同值的总和。
下表展示了一些聚合的表达式:

管道的概念
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
这里我们介绍一下聚合框架中常用的几个操作:
project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。 p r o j e c t : 修 改 输 入 文 档 的 结 构 。 可 以 用 来 重 命 名 、 增 加 或 删 除 域 , 也 可 以 用 于 创 建 计 算 结 果 以 及 嵌 套 文 档 。 match:用于过滤数据,只输出符合条件的文档。 match使用MongoDB的标准查询操作。 m a t c h 使 用 M o n g o D B 的 标 准 查 询 操 作 。 limit:用来限制MongoDB聚合管道返回的文档数。
skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。 s k i p : 在 聚 合 管 道 中 跳 过 指 定 数 量 的 文 档 , 并 返 回 余 下 的 文 档 。 unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
group:将集合中的文档分组,可用于统计结果。 g r o u p : 将 集 合 中 的 文 档 分 组 , 可 用 于 统 计 结 果 。 sort:将输入文档排序后输出。
$geoNear:输出接近某一地理位置的有序文档。
管道操作符实例
1、$project实例
db.article.aggregate(
{ $project : {
title : 1 ,
author : 1 ,
}}
);
这样的话结果中就只还有_id,tilte和author三个字段了,默认情况下_id字段是被包含的,如果要想不包含_id话可以这样:
db.article.aggregate(
{ $project : {
_id : 0 ,
title : 1 ,
author : 1
}});
2.$match实例
db.articles.aggregate( [
{ $match : { score : { $gt : 70, $lte : 90 } } },
{ $group: { _id: null, count: { $sum: 1 } } }
] );
$match用于获取分数大于70小于或等于90记录,然后将符合条件的记录送到下一阶段$group管道操作符进行处理。
3.$skip实例
db.article.aggregate(
{ $skip : 5 });
经过$skip管道操作符处理后,前五个文档被”过滤”掉。
四 Python操作MongoDB
安装PyMongo模块
pip install pymongo
使用MongoClient建立连接
from pymongo import MongoClient
#链接格式
mongodb://[username:password@]host1[:port1][,host2[:port2],...[,hostN[:portN]]][/[database][?options]]
mongodb:// 这是固定的格式,必须要指定。
username:password@ 可选项,如果设置,在连接数据库服务器之后,驱动都会尝试登陆这个数据库
host1 必须的指定至少一个host, host1 是这个URI唯一要填写的。它指定了要连接服务器的地址。如果要连接复制集,请指定多个主机地址。
portX 可选的指定端口,如果不填,默认为27017
/database 如果指定username:password@,连接并验证登陆指定数据库。若不指定,默认打开 test 数据库。
?options 是连接选项。如果不使用/database,则前面需要加上/。所有连接选项都是键值对name=value,键值对之间通过&或;(分号)隔开
# 以下为三种建立无验证连接的方式
#client = MongoClient()
#client = MongoClient('localhost', 27017)
#client = MongoClient('mongodb://localhost:27017/')
#建立验证连接
使用用户 admin 使用密码 123456 连接到本地的 MongoDB 服务上。输出结果如下所示:
> mongodb://admin:123456@localhost/
...
使用用户名和密码连接登陆到指定数据库,格式如下:
mongodb://admin:123456@localhost/test
获取数据库
# 以下是两种获取数据库的方式 db = client.pythondb db = client['python-db']
获取集合
# 以下是两种获取集合的方式 collection = db.python_collection collection = db['python-collection']
上述任何命令都没有在MongoDB服务器上实际执行任何操作。当第一个文档插入集合时才创建集合和数据库。
插入文档
#!/usr/bin/python3
#coding=utf-8
import datetime
from pymongo import MongoClient
client = MongoClient()
db = client.pythondb
posts = db.posts
post = {"author": "Maxsu",
"text": "My first blog post!",
"tags": ["mongodb", "python", "pymongo"],
"date": datetime.datetime.utcnow()}
posts.insert(post)
# 批量插入,参数为list posts.insert_many(new_posts)
查找文档
#!/usr/bin/python3
#coding=utf-8
import datetime
import pprint
from pymongo import MongoClient
client = MongoClient()
db = client.pythondb
posts = db.posts
# 查找单个文档
print(posts.find_one())
# 查找多个文档
for post in posts.find():
print(post)
# 计数统计
print(posts.count())
print(posts.find({"author": "Maxsu"}).count())
到此这篇关于详解MongoDB安装使用并实现Python操作数据库的步骤 的文章就介绍到这了,更多相关MongoDB安装使用内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
