MongoDB数据库基础 查询文档的相关操作介绍
一、查询文档
MongoDB 查询文档使用 find() 方法。以非结构化的方式来显示所有文档。
MongoDB 查询数据的语法格式如下:
- query :可选,使用查询操作符指定查询条件
- projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
如果你需要以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下:
pretty() 方法以格式化的方式来显示所有文档。
实例
以下实例我们查询了集合 col 中的数据:
{
“_id” : ObjectId(“56063f17ade2f21f36b03133”),
“title” : “MongoDB 教程”,
“description” : “MongoDB 是一个 Nosql 数据库”,
“by” : “菜鸟教程”,
“url” : “http://www.runoob.com”,
“tags” : [
“mongodb”,
“database”,
“NoSQL”
],
“likes” : 100
}
除了 find() 方法之外,还有一个 findOne() 方法,它只返回一个文档。
二、条件操作符
MongoDB中条件操作符有:
- (>) 大于 – $gt
- (<) 小于 – $lt
- (>=) 大于等于 – $gte
- (<= ) 小于等于 – $lte
- (!=)不等于 –$ne
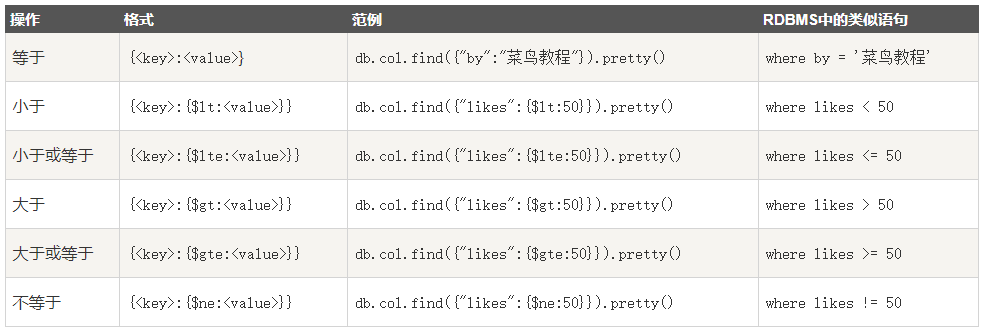
MongoDB 与 RDBMS Where 语句比较
如果你熟悉常规的 SQL 数据,通过下表可以更好的理解 MongoDB 的条件语句查询:
举例:使用 (<) 和 (>) 查询 – $lt 和 $gt
如果你想获取"col"集合中 "likes" 大于100,小于 200 的数据,你可以使用以下命令:
类似于SQL语句:
输出结果:
{ “_id” : ObjectId(“56066549ade2f21f36b0313b”), “title” : “Java 教程”, “description” : “Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言。”, “by” : “菜鸟教程”, “url” : “http://www.runoob.com”, “tags” : [ “java” ], “likes” : 150 }
>
三、AND 条件
MongoDB 的 find() 方法可以传入多个键(key),每个键(key)以逗号隔开,即常规 SQL 的 AND 条件。
语法格式如下:
以下实例通过 by 和 title 键来查询 菜鸟教程 中 MongoDB 教程 的数据
以上实例中类似于 WHERE 语句:WHERE by='菜鸟教程' AND title='MongoDB 教程'
四、OR 条件
MongoDB OR 条件语句使用了关键字 $or,语法格式如下:
{
$or: [ {key1: value1}, {key2:value2}
]
}
).pretty()
以下实例中,我们演示了查询键 by 值为 菜鸟教程 或键 title 值为 MongoDB 教程 的文档。
五、AND 和 OR 联合使用
以下实例演示了 AND 和 OR 联合使用,类似常规 SQL 语句为: 'where likes>50 AND (by = '菜鸟教程' OR title = 'MongoDB 教程')'
六、$type 操作符
描述
条件操作符 $type是基于BSON类型来检索集合中匹配的数据类型,并返回结果。
MongoDB 中可以使用的类型如下表所示:

如果想获取 "col" 集合中 title 为 String 的数据,你可以使用以下命令:
七、Limit与Skip方法
Limit() 方法
如果你需要在MongoDB中读取指定数量的数据记录,可以使用MongoDB的Limit方法,limit()方法接受一个数字参数,该参数指定从MongoDB中读取的记录条数。
limit()方法基本语法如下所示:
以下实例为显示查询文档中的两条记录:
注:如果你们没有指定limit()方法中的参数则显示集合中的所有数据。
Skip() 方法
我们除了可以使用limit()方法来读取指定数量的数据外,还可以使用skip()方法来跳过指定数量的数据,skip方法同样接受一个数字参数作为跳过的记录条数。
skip() 方法脚本语法格式如下:
实例
以下实例只会显示第二条文档数据
注:skip()方法默认参数为 0 。
八、排序
使用 sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。
sort()方法基本语法如下所示:
以下实例演示了 col 集合中的数据按字段 likes 的降序排列:
九、聚合
聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)。
MongoDB中聚合的方法使用aggregate()。
aggregate() 方法的基本语法格式如下所示:
实例
集合中的数据如下:
_id: ObjectId(7df78ad8902c)
title: ‘MongoDB Overview’,
description: ‘MongoDB is no sql database’,
by_user: ‘runoob.com’,
url: ‘http://www.runoob.com’,
tags: [‘mongodb’, ‘database’, ‘NoSQL’],
likes: 100
},
{
_id: ObjectId(7df78ad8902d)
title: ‘NoSQL Overview’,
description: ‘No sql database is very fast’,
by_user: ‘runoob.com’,
url: ‘http://www.runoob.com’,
tags: [‘mongodb’, ‘database’, ‘NoSQL’],
likes: 10
},
{
_id: ObjectId(7df78ad8902e)
title: ‘Neo4j Overview’,
description: ‘Neo4j is no sql database’,
by_user: ‘Neo4j’,
url: ‘http://www.neo4j.com’,
tags: [‘neo4j’, ‘database’, ‘NoSQL’],
likes: 750
},
现在我们通过以上集合计算每个作者所写的文章数,使用aggregate()计算结果如下:
以上实例类似sql语句:
在上面的例子中,我们通过字段 by_user 字段对数据进行分组,并计算 by_user 字段相同值的总和。
下表展示了一些聚合的表达式:

管道的概念
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
这里我们介绍一下聚合框架中常用的几个操作:
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
- $match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
- $geoNear:输出接近某一地理位置的有序文档。
管道操作符实例
1、$project实例
{ $project : {
title : 1 ,
author : 1 ,
}}
);
这样的话结果中就只还有_id,tilte和author三个字段了,默认情况下_id字段是被包含的,如果要想不包含_id话可以这样:
{ $project : {
_id : 0 ,
title : 1 ,
author : 1
}});
2.$match实例
{ $match : { score : { $gt : 70, $lte : 90 } } },
{ $group: { _id: null, count: { $sum: 1 } } }
] );
$match用于获取分数大于70小于或等于90记录,然后将符合条件的记录送到下一阶段$group管道操作符进行处理。
3.$skip实例
{ $skip : 5 });
经过$skip管道操作符处理后,前五个文档被"过滤"掉。
到此这篇关于MongoDB查询文档的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持。

