
性能优化:MySQL如何快速定位慢SQL实战记录
开启慢查询日志
在项目中我们会经常遇到慢查询,当我们遇到慢查询的时候一般都要开启慢查询日志,并且分析慢查询日志,找到慢sql,然后用explain来分析
系统变量
MySQL和慢查询相关的系统变量如下
| 参数 | 含义 |
|---|---|
| slow_query_log | 是否启用慢查询日志, ON为启用,OFF为没有启用,默认为OFF |
| log_output | 日志输出位置,默认为FILE,即保存为文件,若设置为TABLE,则将日志记录到mysql.show_log表中,支持设置多种格式 |
| slow_query_log_file | 指定慢查询日志文件的路径和名字 |
| long_query_time | 执行时间超过该值才记录到慢查询日志,单位为秒,默认为10 |
执行如下语句看是否启用慢查询日志,ON为启用,OFF为没有启用
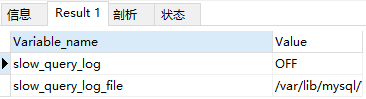
可以看到我的没有启用,可以通过如下两种方式开启慢查询
修改配置文件
修改配置文件my.ini,在[mysqld]段落中加入如下参数
log_output=’FILE,TABLE’
slow_query_log=’ON’
long_query_time=0.001
需要重启 MySQL 才可以生效,命令为 service mysqld restart
设置全局变量
我在命令行中执行如下2句打开慢查询日志,设置超时时间为0.001s,并且将日志记录到文件以及mysql.slow_log表中
set global log_output = ‘FILE,TABLE’;
set global long_query_time = 0.001;
想要永久生效得到配置文件中配置,否则数据库重启后,这些配置失效
分析慢查询日志
因为mysql慢查询日志相当于是一个流水账,并没有汇总统计的功能,所以我们需要用一些工具来分析一下
mysqldumpslow
mysql内置了mysqldumpslow这个工具来帮我们分析慢查询日志。
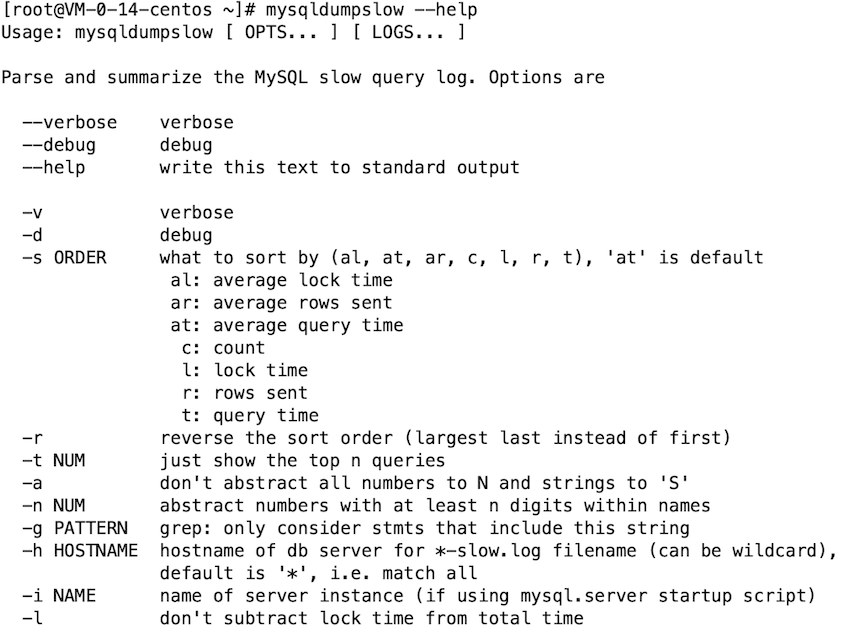
常见用法
mysqldumpslow -s c -t 10 /var/run/mysqld/mysqld-slow.log
# 取出查询时间最慢的3条慢查询
mysqldumpslow -s t -t 3 /var/run/mysqld/mysqld-slow.log
# 得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g “left join” /database/mysql/slow-log
pt-query-digest
pt-query-digest是我用的最多的一个工具,功能非常强大,可以分析binlog、General log、slowlog,也可以通过show processlist或者通过tcpdump抓取的MySQL协议数据来进行分析。pt-query-digest是一个perl脚本,只需下载并赋权即可执行
下载和赋权
chmod u+x pt-query-digest
ln -s /opt/soft/pt-query-digest /usr/bin/pt-query-digest
用法介绍
pt-query-digest –help
// 使用格式
pt-query-digest [OPTIONS] [FILES] [DSN]
常用OPTIONS
–create-review-table 当使用–review参数把分析结果输出到表中时,如果没有表就自动创建。
–create-history-table 当使用–history参数把分析结果输出到表中时,如果没有表就自动创建。
–filter 对输入的慢查询按指定的字符串进行匹配过滤后再进行分析
–limit限制输出结果百分比或数量,默认值是20,即将最慢的20条语句输出,如果是50%则按总响应时间占比从大到小排序,输出到总和达到50%位置截止。
–host mysql服务器地址
–user mysql用户名
–password mysql用户密码
–history 将分析结果保存到表中,分析结果比较详细,下次再使用–history时,如果存在相同的语句,且查询所在的时间区间和历史表中的不同,则会记录到数据表中,可以通过查询同一CHECKSUM来比较某类型查询的历史变化。
–review 将分析结果保存到表中,这个分析只是对查询条件进行参数化,一个类型的查询一条记录,比较简单。当下次使用–review时,如果存在相同的语句分析,就不会记录到数据表中。
–output 分析结果输出类型,值可以是report(标准分析报告)、slowlog(Mysql slow log)、json、json-anon,一般使用report,以便于阅读。
–since 从什么时间开始分析,值为字符串,可以是指定的某个”yyyy-mm-dd [hh:mm:ss]”格式的时间点,也可以是简单的一个时间值:s(秒)、h(小时)、m(分钟)、d(天),如12h就表示从12小时前开始统计。
–until 截止时间,配合—since可以分析一段时间内的慢查询。
常用DSN
A 指定字符集
D 指定连接的数据库
P 连接数据库端口
S 连接Socket file
h 连接数据库主机名
p 连接数据库的密码
t 使用–review或–history时把数据存储到哪张表里
u 连接数据库用户名
DSN使用key=value的形式配置;多个DSN使用,分隔
使用示例
pt-query-digest slow.log
# 分析最近12小时内的查询
pt-query-digest –since=12h slow.log
# 分析指定范围内的查询
pt-query-digest slow.log –since ‘2020-06-20 00:00:00’ –until ‘2020-06-25 00:00:00’
# 把slow.log中查询保存到query_history表
pt-query-digest –user=root –password=root123 –review h=localhost,D=test,t=query_history –create-review-table slow.log
# 连上localhost,并读取processlist,输出到slowlog
pt-query-digest –processlist h=localhost –user=root –password=root123 –interval=0.01 –output slowlog
# 利用tcpdump获取MySQL协议数据,然后产生最慢查询的报表
# tcpdump使用说明:https://blog.csdn.net/chinaltx/article/details/87469933
tcpdump -s 65535 -x -nn -q -tttt -i any -c 1000 port 3306 > mysql.tcp.txt
pt-query-digest –type tcpdump mysql.tcp.txt
# 分析binlog
mysqlbinlog mysql-bin.000093 > mysql-bin000093.sql
pt-query-digest –type=binlog mysql-bin000093.sql
# 分析general log
pt-query-digest –type=genlog localhost.log
用法实战
编写存储过程批量造数据
在实际工作中没有测试性能,我们经常需要改造大批量的数据,手动插入是不太可能的,这时候就得用到存储过程了
`id` int(11) NOT NULL COMMENT ‘用户id’,
`gid` int(11) NOT NULL COMMENT ‘客服组id’,
`name` varchar(25) NOT NULL COMMENT ‘客服名字’
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT=’客户信息表’;
如何定义一个存储过程呢?
BEGIN
需要执行的语句
END
举个例子,插入id为1-100000的100000条数据
用Navicat执行
DROP PROCEDURE IF EXISTS create_kf;
— 开始定义
CREATE PROCEDURE create_kf(IN loop_times INT)
BEGIN
DECLARE var INT;
SET var = 1;
WHILE var < loop_times DO
INSERT INTO kf_user_info (`id`,`gid`,`name`)
VALUES (var, 1000, var);
SET var = var + 1;
END WHILE;
END;
— 调用
call create_kf(100000);
存储过程的三种参数类型
| 参数类型 | 是否返回 | 作用 |
|---|---|---|
| IN | 否 | 向存储过程传入参数,存储过程中修改该参数的值,不能被返回 |
| OUT | 是 | 把存储过程计算的结果放到该参数中,调用者可以得到返回值 |
| INOUT | 是 | IN和OUT的结合,即用于存储过程的传入参数,同时又可以把计算结构放到参数中,调用者可以得到返回值 |
用MySQL执行
得用DELIMITER 定义新的结束符,因为默认情况下SQL采用(;)作为结束符,这样当存储过程中的每一句SQL结束之后,采用(;)作为结束符,就相当于告诉MySQL可以执行这一句了。但是存储过程是一个整体,我们不希望SQL逐条执行,而是采用存储过程整段执行的方式,因此我们就需要定义新的DELIMITER ,新的结束符可以用(//)或者($$)
因为上面的代码应该就改为如下这种方式
CREATE PROCEDURE create_kf_kfGroup(IN loop_times INT)
BEGIN
DECLARE var INT;
SET var = 1;
WHILE var <= loop_times DO
INSERT INTO kf_user_info (`id`,`gid`,`name`)
VALUES (var, 1000, var);
SET var = var + 1;
END WHILE;
END //
DELIMITER ;
查询已经定义的存储过程
开始执行慢sql
select * from kf_user_info where id = 99999;
update kf_user_info set gid = 2000 where id = 8888;
update kf_user_info set gid = 2000 where id = 88888;
可以执行如下sql查看慢sql的相关信息。
查看一下慢日志存储位置
执行后的文件如下
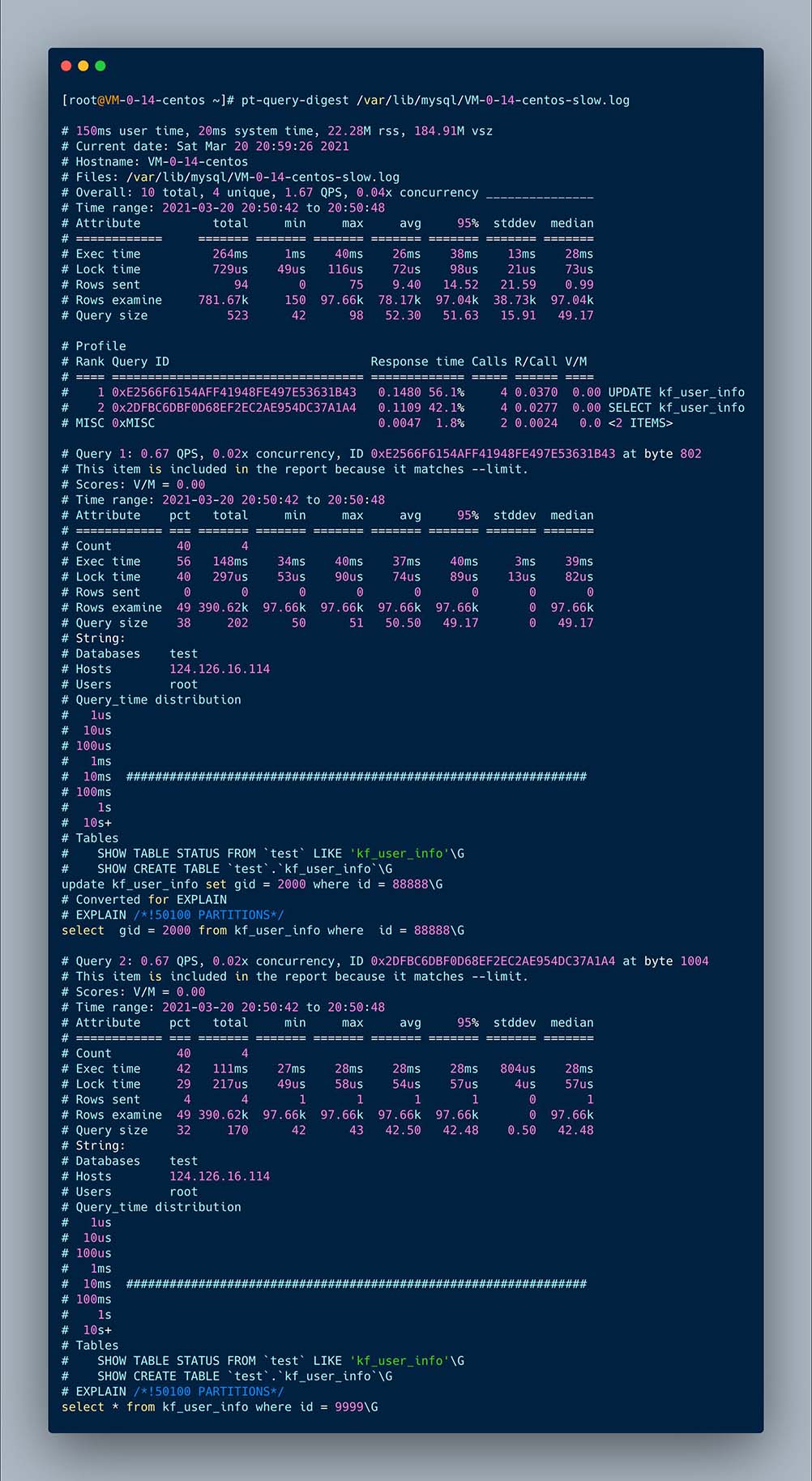
# Rank Query ID Response time Calls R/Call V/M
# ==== =================================== ============= ===== ====== ====
# 1 0xE2566F6154AFF41948FE497E53631B43 0.1480 56.1% 4 0.0370 0.00 UPDATE kf_user_info
# 2 0x2DFBC6DBF0D68EF2EC2AE954DC37A1A4 0.1109 42.1% 4 0.0277 0.00 SELECT kf_user_info
# MISC 0xMISC 0.0047 1.8% 2 0.0024 0.0 <2 ITEMS>
从最上面的统计sql中就可以看到执行慢的sql
可以看到响应时间,执行次数,每次执行耗时(单位秒),执行的sql
下面就是各个慢sql的详细分析,比如,执行时间,获取锁的时间,执行时间分布,所在的表等信息
不由得感叹一声,真是神器,查看慢sql超级方便
最后说一个我遇到的一个有意思的问题,有一段时间线上的接口特别慢,但是我查日志发现sql执行的很快,难道是网络的问题?
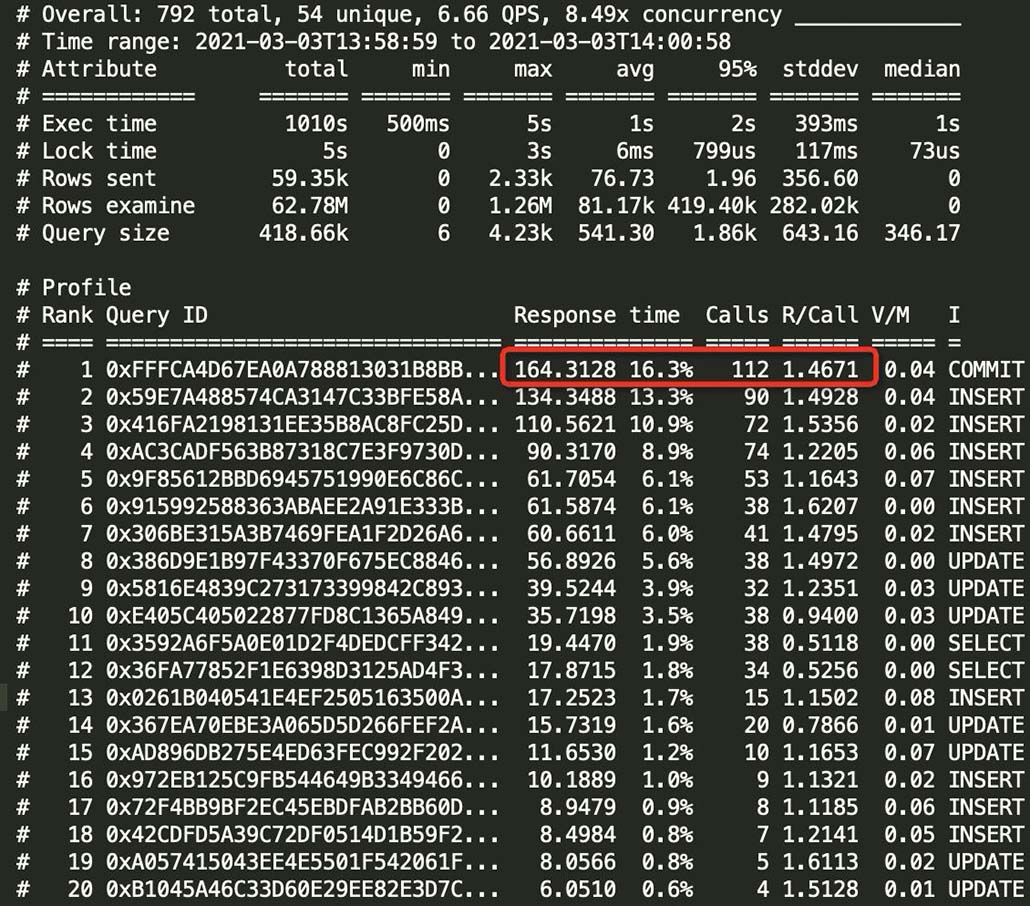
为了确定是否是网络的问题,我就用拦截器看了一下接口的执行时间,发现耗时很长,考虑到方法加了事务,难道是事务提交很慢?
于是我用pt-query-digest统计了一下1分钟左右的慢日志,发现事务提交的次很多,但是每次提交事务的平均时长是1.4s左右,果然是事务提交很慢。
参考博客
很全的一篇文章
[0]https://zhuanlan.zhihu.com/p/106405711
[1]https://blog.csdn.net/lt326030434/article/details/109222848
[1]https://tech.meituan.com/2014/06/30/mysql-index.html
[2]https://blog.csdn.net/itguangit/article/details/82145322
[3]https://mp.weixin.qq.com/s/_SWewX-8nFam20Wcg6No1Q
下载
[4]https://www.cnblogs.com/zi-xing/p/4269854.html
总结
到此这篇关于性能优化:MySQL如何快速定位慢SQL实战记录的文章就介绍到这了,更多相关MySQL快速定位慢SQL内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
