
SQL开发知识:详细聊一聊mysql的树形结构存储以及查询
序
本文主要研究一下mysql的树形结构存储及查询
存储parent
这种方式就是每个节点存储自己的parent_id信息
- 建表及数据准备
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL,
`parent_id` int(11) NOT NULL DEFAULT ‘0’,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
INSERT INTO `menu` (`id`, `name`, `parent_id`) VALUES
(1, ‘level1a’, 0),
(2, ‘level1b’, 0),
(3, ‘level2a-1a’,1),
(4, ‘level2b-1a’,1),
(5, ‘level2a-1b’, 2),
(6, ‘level2b-1b’, 2),
(7, ‘level3-2a1a’, 3),
(8, ‘level3-2b1a’, 4),
(9, ‘level3-2a1b’, 5),
(10, ‘level3-2b1b’, 6);
- 查询
SELECT t1.name AS lev1, t2.name as lev2, t3.name as lev3
FROM menu AS t1
LEFT JOIN menu AS t2 ON t2.parent_id = t1.id
LEFT JOIN menu AS t3 ON t3.parent_id = t2.id
WHERE t1.name = ‘level1a’;
+———+————+————-+
| lev1 | lev2 | lev3 |
+———+————+————-+
| level1a | level2a-1a | level3-2a1a |
| level1a | level2b-1a | level3-2b1a |
+———+————+————-+
— 查询叶子节点
SELECT t1.name FROM
menu AS t1 LEFT JOIN menu as t2
ON t1.id = t2.parent_id
WHERE t2.id IS NULL;
+————-+
| name |
+————-+
| level3-2a1a |
| level3-2b1a |
| level3-2a1b |
| level3-2b1b |
+————-+
存储及修改上比较方便,就是要在sql里头查询树比较费劲,一般是加载到内存由应用自己构造
存储path
这种方式在存储parent的基础上,额外存储path,即从根节点到该节点的路径
- 建表及数据准备
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL,
`parent_id` int(11) NOT NULL DEFAULT ‘0’,
`path` varchar(255) NOT NULL DEFAULT ”,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
INSERT INTO `menu_path` (`id`, `name`, `parent_id`, `path`) VALUES
(1, ‘level1a’, 0, ‘1/’),
(2, ‘level1b’, 0, ‘2/’),
(3, ‘level2a-1a’,1, ‘1/3’),
(4, ‘level2b-1a’,1, ‘1/4’),
(5, ‘level2a-1b’, 2, ‘2/5’),
(6, ‘level2b-1b’, 2, ‘2/6’),
(7, ‘level3-2a1a’, 3, ‘1/3/7’),
(8, ‘level3-2b1a’, 4, ‘1/4/8’),
(9, ‘level3-2a1b’, 5, ‘2/5/9’),
(10, ‘level3-2b1b’, 6, ‘2/6/10’);
- 查询
select * from menu_path where path like ‘1/%’
+—-+————-+———–+——-+
| id | name | parent_id | path |
+—-+————-+———–+——-+
| 1 | level1a | 0 | 1/ |
| 3 | level2a-1a | 1 | 1/3 |
| 4 | level2b-1a | 1 | 1/4 |
| 7 | level3-2a1a | 3 | 1/3/7 |
| 8 | level3-2b1a | 4 | 1/4/8 |
+—-+————-+———–+——-+
查找某个节点及其子节点比较方面,就是修改比较费劲,特别是节点移动,所有子节点的path都得跟着修改
MPTT(Modified Preorder Tree Traversal)
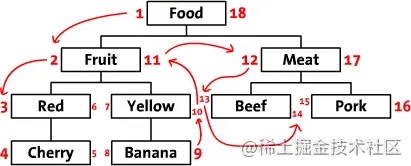
不存储parent_id,改为存储lft,rgt,它们的值由树的先序遍历顺序决定
- 建表及数据准备
`id` int(11) NOT NULL,
`name` varchar(50) NOT NULL,
`lft` int(11) NOT NULL DEFAULT ‘0’,
`rgt` int(11) NOT NULL DEFAULT ‘0’,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
1(level1a)14
2(level2a)7 8(level2b)13
3(level3a-2a)4 5(level3b-2a)6 9(level3c-2b)10 11(level3d-2b)12
INSERT INTO `menu_preorder` (`id`, `name`, `lft`, `rgt`) VALUES
(1, ‘level1a’, 1, 14),
(2, ‘level2a’,2, 7),
(3, ‘level2b’,8, 13),
(4, ‘level3a-2a’, 3, 4),
(5, ‘level3b-2a’, 5, 6),
(6, ‘level3c-2b’, 9, 10),
(7, ‘level3d-2b’, 11, 12);
select * from menu_preorder
+—-+————+—–+—–+
| id | name | lft | rgt |
+—-+————+—–+—–+
| 1 | level1a | 1 | 14 |
| 2 | level2a | 2 | 7 |
| 3 | level2b | 8 | 13 |
| 4 | level3a-2a | 3 | 4 |
| 5 | level3b-2a | 5 | 6 |
| 6 | level3c-2b | 9 | 10 |
| 7 | level3d-2b | 11 | 12 |
+—-+————+—–+—–+
- 查询
select * from menu_preorder where lft between 8 and 13
+—-+————+—–+—–+
| id | name | lft | rgt |
+—-+————+—–+—–+
| 3 | level2b | 8 | 13 |
| 6 | level3c-2b | 9 | 10 |
| 7 | level3d-2b | 11 | 12 |
+—-+————+—–+—–+
— 查询所有叶子节点
SELECT name
FROM menu_preorder
WHERE rgt = lft + 1;
+————+
| name |
+————+
| level3a-2a |
| level3b-2a |
| level3c-2b |
| level3d-2b |
+————+
— 查询某个节点及其父节点
SELECT parent.*
FROM menu_preorder AS node,
menu_preorder AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
AND node.name = ‘level2b’
ORDER BY parent.lft;
+—-+———+—–+—–+
| id | name | lft | rgt |
+—-+———+—–+—–+
| 1 | level1a | 1 | 14 |
| 3 | level2b | 8 | 13 |
+—-+———+—–+—–+
— 树形结构展示
SELECT CONCAT( REPEAT(‘ ‘, COUNT(parent.name) – 1), node.name) AS name
FROM menu_preorder AS node,
menu_preorder AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
GROUP BY node.name
ORDER BY node.lft;
+————–+
| name |
+————–+
| level1a |
| level2a |
| level3a-2a |
| level3b-2a |
| level2b |
| level3c-2b |
| level3d-2b |
+————–+
好处是通过lft进行范围(该节点的lft,rgt作为范围)查找就可以,缺点就是增删节点导致很多节点的lft及rgt都要修改
小结
- 存储parent的方式最为场景,一般树形结构数据量不大的话,直接在应用层内存构造树形结构和搜索
- 存储path的好处是可以借助path来查找节点及其子节点,缺点就是移动node需要级联所有子节点的path,比较费劲
- MPTT的方式好处是通过lft进行范围(该节点的lft,rgt作为范围)查找就可以,缺点就是增删节点导致很多节点的lft及rgt都要修改
doc
- Managing Hierarchical Data in MySQL
- hierarchical-data-database
- hierarchical-data-database-2
- hierarchical-data-database-3
到此这篇关于mysql树形结构存储以及查询的文章就介绍到这了,更多相关mysql树形结构存储及查询内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
