
SQL开发知识:MySQL分区之HASH分区详解
介绍
基于给定的分区个数,将数据分配到不同的分区,HASH分区只能针对整数进行HASH,对于非整形的字段只能通过表达式将其转换成整数。表达式可以是mysql中任意有效的函数或者表达式,对于非整形的HASH往表插入数据的过程中会多一步表达式的计算操作,所以不建议使用复杂的表达式这样会影响性能。
MYSQL支持两种HASH分区,常规HASH(HASH)和线性HASH(LINEAR HASH)。
一、常规HASH
常规hash是基于分区个数的取模(%)运算。根据余数插入到指定的分区
id INT NOT NULL,
store_id INT
)
PARTITION BY HASH(store_id)
PARTITIONS 4
;
SELECT PARTITION_NAME,PARTITION_METHOD,PARTITION_EXPRESSION,PARTITION_DESCRIPTION,TABLE_ROWS,SUBPARTITION_NAME,SUBPARTITION_METHOD,SUBPARTITION_EXPRESSION
FROM information_schema.PARTITIONS WHERE TABLE_SCHEMA=SCHEMA() AND TABLE_NAME=’tbhash’;

其中100,104对4取模是0所以这两条数据被分配到了p0分区。

2.时间类型字段
id INT NOT NULL,
hired DATE NOT NULL DEFAULT ‘1970-01-01’,
)
PARTITION BY HASH( YEAR(hired) )
PARTITIONS 4;
常规hash的分区非常的简便,通过取模的方式可以让数据非常平均的分布每一个分区,但是由于分区在创建表的时候已经固定了。如果新增或者收缩分区的数据迁移比较大。
二、线性HASH(LINEAR HASH)
LINEAR HASH和HASH的唯一区别就是PARTITION BY LINEAR HASH
id INT NOT NULL,
hired DATE NOT NULL DEFAULT ‘1970-01-01’
)
PARTITION BY LINEAR HASH( YEAR(hired) )
PARTITIONS 6;
线性HASH的计算原理如下:
假设分区个数num=6,N表示数据最终存储的分区
sep1:V = POWER(2, CEILING(LOG(2, num))),LOG()是计算NUM以2为底的对数,CEILING()是向上取整,POWER()是取2的次方值;如果num的值是2的倍数那么这个表达式计算出来的结果不变。
V=POWER(2,CEILING(LOG(2,6)))
V=POWER(2,3)
V=8
sep2:N=values&(V-1);&位与运算,将两个值都转换成2进行求与运算,当都为1才为1;当num是2的倍数时由于V计算出来的结果不变,这时values&(V-1)=MOD(values/num)和时间HASH取模算出的结果是一致的,这时特殊情况只有当分区是2的倍数才是这种 情况。values是YEAR(hired)的值
sep3:while N>=num
sep3-1:N=N& (CEIL(V/ 2)- 1)
例如:
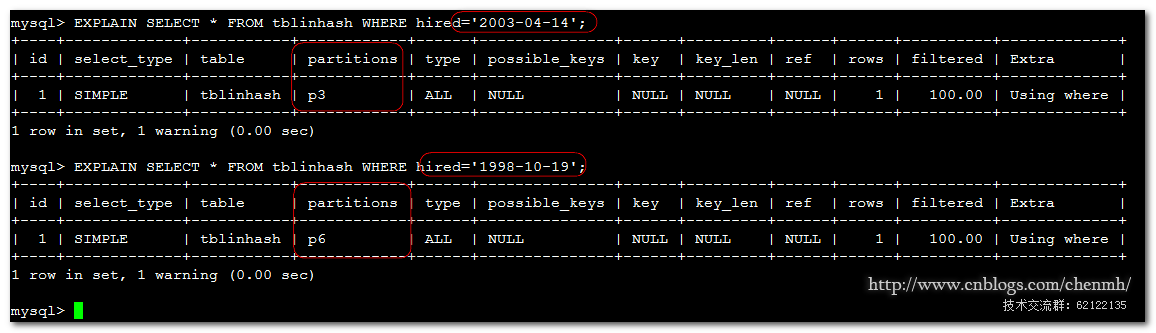
1.当插入的值是'2003-04-14'时
V = POWER(2, CEILING( LOG(2,6) )) = 8
N = YEAR('2003-04-14') & (8 – 1)
= 2003 & 7
=3
(3 >= 6 is FALSE: record stored in partition #3),N不大于num所以存储在第3分区,注意这里的3指的是P3,分区号是从P0开始。
2.当插入的值是‘1998-10-19’
V = POWER(2, CEILING( LOG(2,6) )) = 8
N = YEAR('1998-10-19') & (8-1)
= 1998 & 7
= 6
(6 >= 6 is TRUE: additional step required),由于N>=num所以要进行第三步操作
N=N&(CEILING(8/2)-1)
=6&3
=2
(2>=6is FALSE:recored in partition #2),由于2不大于6所以存储在第2个分区,注意这里的3指的是P2,分区号是从P0开始。
SELECT PARTITION_NAME,PARTITION_METHOD,PARTITION_EXPRESSION,PARTITION_DESCRIPTION,TABLE_ROWS,SUBPARTITION_NAME,SUBPARTITION_METHOD,SUBPARTITION_EXPRESSION
FROM information_schema.PARTITIONS WHERE TABLE_SCHEMA=SCHEMA() AND TABLE_NAME=’tblinhash’;


三、分区管理
常规HASH和线性HASH的增加收缩分区的原理是一样的。增加和收缩分区后原来的数据会根据现有的分区数量重新分布。HASH分区不能删除分区,所以不能使用DROP PARTITION操作进行分区删除操作;
只能通过ALTER TABLE … COALESCE PARTITION num来合并分区,这里的num是减去的分区数量;
可以通过ALTER TABLE … ADD PARTITION PARTITIONS num来增加分区,这里是null是在原先基础上再增加的分区数量。
1.合并分区
减去3个分区
FROM information_schema.PARTITIONS WHERE TABLE_SCHEMA=SCHEMA() AND TABLE_NAME=’tblinhash’;

注意:减去两个分区后,数据根据现有的分区进行了重新的分布,以'2003-04-14'为例:POWER(2, CEILING( LOG(2,3) ))=4,2003&(4-1)=3,3>=3,3&(CEILING(3/2)-1)=1,所以现在的'2003-04-14'这条记录由原来的p3变成了p1

2.增加分区
增加4个分区
FROM information_schema.PARTITIONS WHERE TABLE_SCHEMA=SCHEMA() AND TABLE_NAME=’tblinhash’;

当在3个分区的基础上增加4个分区后,‘2003-04-14’由原来的p1变成了p3,而另一条记录由原来的p2变成了p6
四、移除表的分区
REMOVE PARTITIONING ;
注意:使用remove移除分区是仅仅移除分区的定义,并不会删除数据和drop PARTITION不一样,后者会连同数据一起删除
分区系列文章:
总结
常规HASH的数据分布更加均匀一些,也便于理解;目前还没有彻底理解为什么线性HASH在收缩和增加分区时处理的速度会更快,同时线性HASH的数据分布不均匀。
到此这篇关于MySQL分区之HASH分区的文章就介绍到这了,更多相关MySQL HASH分区内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
